Videos
- Oxygen Web Author 28
- Oxygen Content Fusion 9
- Oxygen XML Editor 28
- Oxygen AI Positron
- Oxygen XML Editor 27
- Oxygen Web Author 27
- Oxygen Feedback 5
- Oxygen Content Fusion 7
- Oxygen XML Editor 26
- Oxygen AI Positron 1
- Oxygen Feedback 4
- Oxygen XML Web Author 26
- Oxygen XML Editor 25
- Oxygen XML Editor 24
- Oxygen Feedback 2
- Oxygen Content Fusion 4
- Oxygen Feedback 1
- Oxygen XML Web Author 23
- Oxygen XML Web Author 21
- Visual XML Editing
- XML Editing
- XSLT Editing
- JSON
- XML Development
- XSLT Transformations
- Schema Editing
- XQuery Debugging
- WSDL Support
- SharePoint & WebDAV Support
- XML & Relational Databases
- Editing OOXML Documents
- Tools
Video demonstrations
- Oxygen XML Editor 28
- Oxygen XML Web Author 27
- Oxygen Positron 6
- Oxygen Content Fusion 8
- Oxygen XML Editor 27
- Oxygen Feedback 5
- Oxygen XML Editor 26
- Oxygen Feedback 4
- Oxygen XML Web Author 26
- Oxygen Content Fusion 6
- Oxygen Feedback 3
- Oxygen XML Editor 25
- Oxygen XML Editor 24
- Oxygen Feedback 2
- Oxygen XML Editor 23
- Oxygen Feedback 1
- Oxygen XML Editor 22
- Oxygen XML Editor 21
- Oxygen Content Fusion
- Oxygen XML Editor 20
- Oxygen XML Editor 19
- Oxygen XML Editor 18
- Oxygen XML Editor 17
- XSLT Development with Oxygen
- DITA Support in Oxygen
- XML Authoring for Everyone
- Others
Webinars
Filter by Category
- Videos
- Webinars
- Conferences
Filter by Product
- Oxygen XML Editor
- Oxygen WebHelp
- Oxygen XML Author
- Oxygen PDF Chemistry
- Oxygen XML Developer
- Oxygen Feedback
- Oxygen JSON Editor
- Oxygen XML Web Author
- Oxygen AI Positron
- Oxygen Content Fusion
- Oxygen Publishing Engine
- Oxygen Scripting
Filter by Technology
- XML
- XSLT
- Schema
- DITA
- TEI
- DocBook
- EPUB
- WebHelp
- XQuery
- WSDL
- SharePoint
- Databases
- Mobile
- JSON
- Markdown
- CSS
Video demonstrations
Oxygen Web Author 28

This short video demonstrates one of the new features added in Oxygen XML Web Author 28.1, showing that it is now easier to work with large DITA tables because headers remain visible while scrolling and an internal scrollbar helps you to navigate large tables without losing context.
- Oxygen
- XML
- Editor
- Web
- Author

This short video demonstrates one of the new features added in Oxygen XML Web Author 28.1, showing how profiling styles and flags that are defined in a DITAVAL file are now applied directly in the visual editor and the DITA Map pane, allowing you to use different colors and text styles to visually distinguish profiled content based on attribute values.
- Oxygen
- XML
- Editor
- Web
- Author

This short video demonstrates one of the new features added in Oxygen XML Web Author 28, showing how to enable an option that allows you to clearly see whitespace marks in the editor.
- Oxygen
- XML
- Editor
- Web
- Author

This short video demonstrates one of the new features added in Oxygen XML Web Author 28, showing how you can utilize the integrated AI assistance to efficiently create a new document.
- Oxygen
- XML
- Editor
- Web
- Author
Oxygen Content Fusion 9

Learn how to set up a Content Fusion Cloud organization from scratch. In this video, you’ll see how to create an organization, invite users, configure license settings, and manage authentication options to ensure your team can collaborate efficiently and securely.
- Oxygen
- version 9

See how to go from raw input provided by SMEs to a fully published documentation site in just 10 minutes using Content Fusion Cloud. Starting with stakeholder-provided materials, you’ll learn how to create structured DITA content using AI and how to publish it as a modern WebHelp output — all within a streamlined, end-to-end workflow.
- Oxygen
- version 9

Discover how to transform your WebHelp site published from Oxygen Content Fusion into an AI-powered knowledge experience. In this demo, you’ll see how Oxygen Feedback adds semantic search, an AI assistant, and intelligent search summaries — turning static documentation into a smart, conversational support resource.
- Oxygen
- version 9
Oxygen XML Editor 28
This is a short video for one of the new features added in Oxygen XML Editor 28, demonstrating how you can utilize the integrated AI assistance to efficiently create a new document. Note that this features requires the Oxygen AI Positron add-on.
- Oxygen
- XML
- Editor
- Developer
- Author

This is a short video for one of the new features added in Oxygen XML Editor 28, demonstrating how to use the DITA Maps Manager's new search filter to quickly find resources.
- Oxygen
- XML
- Editor
- Author

This is a short video for one of the new features added in Oxygen XML Editor 28, demonstrating how to quickly insert links in documents directly from the Open/Find Resources view.
- Oxygen
- XML
- Editor
- Author

This is a short video for one of the new features added in Oxygen XML Editor 28, showing that with the Main Files feature enabled for a DITA project, when attempting to delete a resource, you have the ability to review the list of resources where the item is referenced to prevent broken references.
- Oxygen
- XML
- Editor
- Author
This is a short video for one of the new features added in Oxygen XML Editor 28, demonstrating the new Dark mode support in WebHelp Responsive output.
- Oxygen
- XML
- Editor
- Author

This is a short video highlighting some of the XSLT/XQuery enhancements implemented in Oxygen XML Editor 28.
- Oxygen
- XML
- Editor
- Developer
- Author
This is a short video highlighting some of the XProc enhancements implemented in Oxygen XML Editor 28.
- Oxygen
- XML
- Editor
- Developer
- Author
This is a short video highlighting some of the enhancements implemented for the File and Directory Comparison tools in Oxygen XML Editor 28.
- Oxygen
- XML
- Editor
- Developer
- Author

This is a short video for one of the new features added in Oxygen XML Editor 28, demonstrating the new AI Autocompletion feature that offers intelligent coding assistance as you type in the editor. Note that this features requires the Oxygen AI Positron add-on.
- Oxygen
- XML
- Editor
- Developer
- Author
Oxygen AI Positron

This video presents some of the most interesting features that were implemented in Oxygen AI Positron 5.0.
- Oxygen
- XML
- Editor
- JSON
- Author

This video demonstrates the new Formula/Equation AI action that was introduced in Oxygen AI Positron Assistant 4.1. For more details about the powerful Oxygen AI Positron Assistant, see our webpage: www.oxygenxml.com/ai_positron_assistant.html.
- Oxygen
- XML
- Editor
- JSON
- Author
Oxygen XML Editor 27

This video presents highlights of some of the most interesting new features implemented in Oxygen 27. For a complete list of the additions, updates and implementations go to our What's New page: www.oxygenxml.com/xml_editor/whatisnew27.0.html
- Oxygen
- XML
- Editor
- JSON
- Author
This video demonstrates using Oxygen XML Editor to transform JSON documents into HTML output with XSLT processing and into XML output with XQuery processing. For more technical details, see the 'Transforming and Querying JSON Documents' section in our user manual: www.oxygenxml.com/doc/ug-editor/topics/json-transforming.html.
- Oxygen
- XML
- Editor
- JSON
- Author

This video demonstrates various ways that you can use the "Apply All Default Quick Fix Proposals" tool to apply quick fix proposals for all reported validation errors detected in a single document or to apply them to a batch of multiple documents (for example, all files within a project or a DITA map).
- Oxygen
- XML
- Editor
- Web
- Author
Oxygen Web Author 27

This video demonstrates how to use the Web Author Test Server Add-on in Oxygen XML Editor to quickly preview and test XML framework customizations in a local Web Author environment. In just a few steps, you’ll see how to:
- Install the add-on directly from Oxygen XML Editor
- Launch a local Web Author Test Server with no extra configuration
- Open your current document in the browser using the associated framework
Apply and instantly preview changes, such as custom styling or toolbar actions
Whether you’re starting a new Web Author integration or fine-tuning an existing DITA framework, this add-on streamlines your workflow by removing the need to manually package and deploy customizations.
- Oxygen
- XML
- Editor
- Web
- Author

In this demo, you’ll learn how to enable seamless collaboration with Subject Matter Experts (SMEs) using Oxygen XML Web Author.
First, we’ll demonstrate how an SME can propose changes to content of a published DITA-based publication by simply clicking an Edit Link—taking them directly to the topic in Web Author. Then, we’ll walk through how to generate a publication with embedded Edit Links using Oxygen XML Editor, empowering content creators and tech writers to invite SME contributions with just a click.
This workflow enables anyone to suggest changes, while keeping the content updates in the hands of technical writers, so they can maintain high quality standards.
- Oxygen
- XML
- Editor
- Web
- Author

This video presents several examples for using the diff and merge functionality in Oxygen XML Web Author.
- Oxygen
- XML
- Editor
- Web
- Author

This video presents highlights of some of the most interesting new features implemented in Oxygen XML Web Author 27. For a complete list of the additions, updates and implementations go to our What's New page: www.oxygenxml.com/xml_web_author/whatisnew27.0.html
- Oxygen
- Web Author
Oxygen Feedback 5

This video presents the AI Assistant and AI-Enhanced Search Summary features that were added in Oxygen Feedback 5.0. They allow you to have real-time conversations with the AI Assistant based on the content of your publication, helping you to quickly find more accurate answers and information.
- Oxygen
- version 5.0
- Feedback
Oxygen Content Fusion 7

This video presents some of the most interesting new features implemented in Oxygen Content Fusion 7.0. For a complete list of all the new updates added in this version, visit the Content Fusion what's new page: www.oxygenxml.com/content_fusion/whats_new.html
- Oxygen
- version 7
Oxygen XML Editor 26

This video presents highlights of some of the most interesting new features implemented in Oxygen XML Editor 26. For a complete list of the additions, updates and implementations go to our What's New page: https://www.oxygenxml.com/xml_editor/whats_new.html
- Oxygen
- XML
- Editor
- Web
- Author

This video presents some of the features available in the Oxygen JSON Editor 26.
- Oxygen
- XML
- Editor
- Web
- Author

This video present some of the useful tools and features that are provided in Oxygen to help you work with YAML documents.
- Oxygen
- XML
- Editor
- Web
- Author
Oxygen AI Positron 1

This video provides general information about the Enterprise version of the Oxygen AI Positron Assistant add-on, as well as a demonstration of how to install and configure the add-on.
- Oxygen
- XML
- Editor
- Web
- Author

This video provides an introduction to Oxygen's AI Positron Assistant, a powerful tool to help writers use AI-generated content.
- Oxygen
- XML
- Editor
- Web
- Author
Oxygen Feedback 4

This video teaches you how to replace the default search engine that is used for Oxygen WebHelp Responsive output with a search engine powered by Oxygen Feedback. This enables advanced search functionality, giving users the ability to create complex and flexible queries that generate precise search results.
- Oxygen
- version 4.0
- Feedback

This video demonstrates how to use the "faceted search" functionality when searching Oxygen WebHelp Responsive output after configuring it to use the search engine powered by Oxygen Feedback. A "faceted search" is a powerful and user-friendly search and filtering technique that makes it easy to narrow the results and find specific information within a large documentation project by applying multiple filters or facets simultaneously.
- Oxygen
- version 4.0
- Feedback
 04:23
04:23This video demonstrates how to use content labeling and advanced search queries in Oxygen WebHelp Responsive output after configuring it to use the search engine powered by Oxygen Feedback. This allow users to retrieve more specific and precise information. Content labels make it easy for users to search for topics with the same label by simply clicking on the label presented in the WebHelp Responsive output. Advanced search queries are particularly useful for fine-tuning searches when standard keyword queries yield too many irrelevant results.
- Oxygen
- version 4.0
- Feedback

This video demonstrates how to use semantic search queries in Oxygen WebHelp Responsive output after configuring it to use the search engine powered by Oxygen Feedback. A "semantic search" is an advanced search technique that aims to improve the accuracy and relevance of search results by understanding the context and meaning behind the search query, rather than relying solely on keyword matching.
- Oxygen
- version 4.0
- Feedback
Oxygen XML Web Author 26

This video takes you on a brief tour of Oxygen XML Web Author, showing many of the features and possibilities that are provided by the innovative web-based XML authoring tool.
- Oxygen
- XML
- Editor
- Web
- Author

This video presents highlights of some of the most important and interesting new features implemented in Oxygen XML Web Author 26. Note that you can experiment with the AI Positron Assistant and other features using our demo at https://www.oxygenxml.com/oxygen-xml-web-author/app/oxygen.html For the full list of features added in Web Author 26, go to https://www.oxygenxml.com/xml_web_author/whats_new.html
- Oxygen
- XML
- Editor
- Web
- Author
Oxygen XML Editor 25

This video presents some ways that Oxygen XML Web Author can be used in various stages of a
documentation review workflow to help make your processes easier and more efficient. This
video demonstrates how Web Author can be integrated with WebHelp output to provide a quick,
easy way to view a document in editing mode and how Web Author can be integrated with the
JIRA issue/project tracking application to provide links for reviewers to see a comparison
of document changes or the source document.
User Guide topic:
Embedding an Edit Link that will Launch Web Author
For more details about Web Author's file comparison tool, see our video:
Using Oxygen XML Web Author's Diff Functionality
- Oxygen
- XML
- Editor
- Web
- Author

The purpose of this video is to demonstrate how to use Search and Refactoring type actions in Oxygen's JSON Schema Design mode.
- Oxygen
- XML
- Editor
- Web
- Author

The purpose of this video is to demonstrate how you can integrate REST-API content that is documented using the OpenAPI standard into your DITA documentation using some Oxygen tools and features.
- Oxygen
- XML
- Editor
- Web
- Author

The purpose of this video is to present the features that are available in Oxygen for JSON schema documents that are set to version 2020-12.
- Oxygen
- XML
- Editor
- Web
- Author

This video presents highlights of some of the most important and interesting new features implemented in Oxygen 25.
- Oxygen
- XML
- Editor
- Web
- Author

This video presents highlights of some of the most interesting new features implemented in Oxygen XML Web Author 25.
- Oxygen
- XML
- Editor
- Web
- Author

This video shows some of the editing features that are available in Oxygen when working with OpenAPI documents.
- Oxygen
- XML
- Editor
- Web
- Author

This video shows how to use scripts from a command-line tool to validate documents.
- Oxygen
- XML
- Editor
- Web
- Author

This video shows how to use scripts from a command-line tool to validate documents.
- Oxygen
- XML
- Editor
- Web
- Author
Oxygen XML Editor 24

This video presents some of the new features implemented in Oxygen XML Web Author 24.1
- Oxygen
- XML
- Editor
- Web
- Author

This video demonstrates some of the useful features that are available in Oxygen's JSON Schema Design mode when using it in conjunction with the Palette view to create a JSON schema.
- Oxygen
- XML
- Editor
- Web
- Author

This short video shows you how easy it is to convert Confluence content to DITA documents using Oxygen's Batch Documents Converter.
- Oxygen
- XML
- Editor
- Web
- Author

This video presents some of the most important and interesting new features and updates implemented in Oxygen 24. For a complete list of the additions, updates and implementations go to our What's New page: https://www.oxygenxml.com/whatisnew24.1.html
- Oxygen
- XML
- Editor
- Web
- Author

This video presents some of the new features implemented in Oxygen XML Web Author 24.
- Oxygen
- XML
- Editor
- Web
- Author
This video offers a brief tutorial for how to publish content originating from Oxygen to the Zendesk Help Center.
- Oxygen
- XML
- Editor
- Web
- Author
This video offers a brief demonstration of Oxygen XML Web Author's merge tool.
- Oxygen
- XML
- Editor
- Web
- Author
This video offers a demonstration of using tools within Oxygen XML Editor to generate file or directory comparison reports in various formats.
- Oxygen
- XML
- Editor
- Compare

This video offers a demonstration of using scripts from a command-line tool to compare files and generating comparison reports in various formats.
- Oxygen
- XML
- Editor
- Compare

This video offers a demonstration of using scripts from a command-line tool to compare directories and generating comparison reports in various formats.
- Oxygen
- XML
- Editor
- Compare
This video provides an introduction to Oxygen's JSON Schema Design mode, demonstrating some of this mode's useful features and possibilities.
- Oxygen
- XML
- Editor
Oxygen Feedback 2

This video shows how to install the Oxygen Feedback commenting component in published WebHelp output using a transformation scenario in Oxygen XML Editor or Oxygen XML Author.
- Oxygen
- version 2.0
- Feedback
Oxygen Content Fusion 4

This video presents some of the most requested and exciting new features added in Oxygen Content Fusion 4. For a complete list of the additions, updates and implementations go to our What's New page: https://www.oxygenxml.com/content_fusion/whats_new.html
- Oxygen
- version 23
Oxygen Feedback 1
This video provides a brief overview of the block-level comments feature that allows your users to add and manage comments contextually.
- Oxygen
- version 1.4
- Feedback

This video presents an overview of the benefits of the Oxygen Feedback commenting platform that provides a simple and efficient way for your community to interact and offer feedback.
- Oxygen
- version 1.2
- Feedback

Introducing the Oxygen Feedback Comment Management Platform
- FeedBack
Oxygen XML Web Author 23
This video provides a brief overview of the Oxygen Styles Basket, a web-based visual tool that helps you customize the look and style of your PDF or WebHelp output.
- Oxygen
- Styles
- Basket

This video presents some of the most requested and exciting new features added in Oxygen 23, the most powerful and comprehensive version of the Oxygen suite of products to date.
- Oxygen
- version 23

This video presents some of the most requested and exciting new features added in Oxygen XML Web Author 23. For a complete list of the additions, updates and implementations go to our What's New page: https://www.oxygenxml.com/xml_web_author/whatisnew23.0.html
- Oxygen
- version 23

This video presents some of the new features in Oxygen XML Editor 22.
- Oxygen
- version 22

Oxygen XML Web Author 22
This video presents some of the new features in Oxygen XML Web Author 22.
- Oxygen
- version 22

This video presents some of the new features in What's New in Oxygen Content Fusion 2.0.
- Oxygen
- version 22

This video presents some of the new features in Oxygen XML Editor 21.
- Oxygen
- version 21

This video presents some of the new features in Oxygen XML Editor 20.
- Oxygen
- version 20

This video presents some real world use-cases for using Oxygen XML Web Author to improve documentation quality, team efficiency, and the review process.
- XML Web Author

This video presents some of the new features in Oxygen XML Editor 19.
- Oxygen
- version 19
This video presents Oxygen Content Fusion, a flexible, intuitive collaboration platform designed to adapt to virtually any type of workflow that a collaborative team may use for their documentation.
- Oxygen
- Content Fusion
Oxygen XML Web Author 21

This video presents some of the new features in Oxygen XML Web Author 21.1.1.
- what's new 21.1.1
- File Comparison Tool
- Drag and Drop Functionality
- DITA Map View

This video shows how simple and efficient it is to review content in a browser using Oxygen XML Web Author.
- Oxygen
- web author
- review
- manage changes
- track changes

This video shows some of the advanced editing features in Oxygen XML Web Author, as well as some possibilities for customizing your authoring experience.
- oxygen
- web author
- advanced editing
- form controls
- image map
Visual XML Editing
This video presents Oxygen's support for conditional profiling attribute groups, a feature that was introduced in version 21.0. The video shows how to create and use custom attribute groups for filtering and flagging content in the interface and the output.
- DITA Maps Manager
- Profiling Condition Sets
- Content Reference (conref) ranges
This demonstration shows you how to use the DITA Reusable Components view in Oxygen XML Editor. This view is helpful for DITA documentation projects that utilize a large amount of keys and reusable components.
- oxygen
- DITA
- DITA Reusable Components
- keys
This demonstration shows you the fastest ways to create new DITA topics and how to convert existing DITA documents to another type.
- DITA
- fast create
- convert DITA
This video presents the Markdown Editor that is available in Oxygen XML, allowing you to convert Markdown syntax to HTML or DITA. Aside from the plain text syntax that is common among most Markdown applications, the Markdown editor also integrates many other powerful features that content authors are accustomed to using for other types of documents.
- Markdown
- Convert Markdown to DITA
- Convert Markdown to HTML
- DitaMap
This video presents the possibility of using media form controls in Oxygen XML to play video content, both when editing in the Author mode and in any HTML5-based output.
- Media objects
- embed video
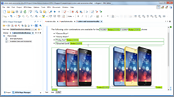
This video presents two new features of DITA 1.3 (key scopes and branch filtering) that allow you to maximize the reuse possibilities for keys in topics and reuse the content of topics multiple times within the same map, each time using a different filter.
- DITA 1_3
- Visual XML Authoring
- Publish
- Key scopes
- Branch filtering
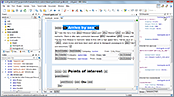
This video presents the CSS Inspector view that allows you to analyze and change the styles of XML elements.
- CSS
- Visual XML Authoring
- CSS Inspect
- Inspect Styles
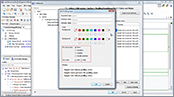
This video highlights the features that improve the existing profiling support. You will learn how you can customize the Author editing mode to mark profiled content so that you can instantly spot different variants of the output.
- Colors and Styles
- Profiled Content
- Share Profiling Settings
- Show Excluded Content
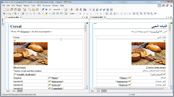
This video demonstration presents the bidirectional editing support offered by Oxygen.
- Unicode Bidirectional Algorithm
- Directional Formatting Codes
- Right-to-Left editing
- Arabic
- Hebrew
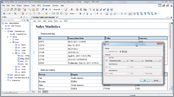
This video presentation walks you through the content sorting support for tables and lists offered by Oxygen.
- Sort tables
- Sort lists
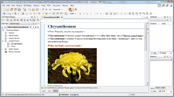
This video demonstration shows you how to avoid validation problems in your DITA Maps using the Root Map support to establish a key space, which you can use with any DITA Map that is imported by the Master File.
- Providing context to work with DITA 1.2 keys
- Defining key spaces
- Setting the scope for map wide operations
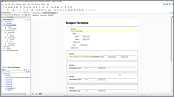
This video demonstration shows you the basics of using a DITA Subject Scheme Map to create and manage custom profiling values that allow you to filter content in Oxygen's Author mode or in transformed output.
- Control attribute values
- Hierarchical profiling values
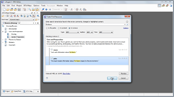
This demonstration walks you through the Open/Find Resource dialog box search capabilities, from simple text searches to the more complex queries involving wildcards, boolean operators, searching in reviews, and more.
- Searching in file path
- Search in content
- XML-aware search
- Boolean operators
The Review view is designed to offer an enhanced way of monitoring all the changes that you make to an XML document. You are able to view and manage highlights, comments, and tracked changes from a single panel.
- Review
- Change Tracking
- Comments
In this video demonstration you will see how you can use the Highlight tool to mark fragments of text in a document you are editing. Using this tool you can easily draw attention to important content.
- Highlight text
- Review panel
- Predefined colors
This demonstration presents the support for editing attributes and simple element values in the Author mode using form controls.
- Form Controls
- Visual editing of attributes and elements
- Author page customization through CSS
This video demonstration shows you how to use the review support in Oxygen. This support includes actions that allow you to add and manage comments, reply to them, and mark them as being done.
- Callouts
- Collaboration
- Reply to comments
- Mark as done
- Manage comments
This demonstration shows how Oxygen converts unstructured content copied from various sources (such as web pages and Microsoft Office documents) into valid structured DITA content. This capability is also available in other documentation frameworks embedded in Oxygen (for example, DocBook, TEI, and XHTML).
- Copy Content from Browsers
- Copy Content from Microsoft Word
- Copy Content from Microsoft Excel
This demonstration shows how easy it is to debug errors found in a DITA Map.
- DITA Maps Manager
- Validate & Check for Completness
- Content Reference (conref) ranges
This demonstration shows how DITA Map content can be filtered using profiling attributes.
- DITA Maps Manager
- Profiling Condition Sets
- Content Reference (conref) ranges
This demonstration shows how profiling and conditional text can be used in the DocBook publishing process.
- Profiling
- Condition Sets
- Profiling Attributes
- Transformation scenario
This demonstration highlights the EPUB support in Oxygen.
- Transformation scenario
- DITA to EPUB
- DocBook to EPUB
- Validate the EPUB file
This demonstration describes the DITA 1.2 editing support in Oxygen.
- DITA Maps Manager
- Content Reference (conref) ranges
- Linking with keyref
- Image reference with keyref
- Content key references
- Find/Replace in Files
- Check Spelling in Files
This demonstration covers the basic aspects of the change tracking mechanism implemented in Oxygen.
- Change tracking
- DITA
- Visual editing
This demonstration covers the basics of editing DocBook documents in Author mode.
- Visual editing of a Docbook document
- Insert tables and images
- Text formatting
- Transform to PDF
This demonstration shows how the Oxygen DITA Editor allows users with limited knowledge of XML to edit DITA documents in a similar way as a regular word processing application.
- Visual DITA editing
- Predefined DITA templates
- DITA conref
- Insert a table
- PDF publishing
This video presents some of the unique and helpful features that you will find in the powerful DITA Maps Manager. Among other things, it will show you the basics of managing DITA maps, the Edit Properties dialog box, adding topic references, and publishing DITA maps.
- DITA Maps Manager
- Organizing Maps
- Edit Properties Dialog Box
- Insert References
- Publish DITA Maps
This demonstration will guide you through the basics of using the Oxygen's Author mode, which allows you to edit XML documents in a visual interface similar to a What You See Is What You Get word processor.
- Visual editing
- Customizable Author actions
- Transformation scenario
- DITA
- DocBook
- TEI
- Styles
- Associate CSS
XML Editing
This demonstration shows you how you can use the rectangular selection feature to edit column-like formatted text in Oxygen.
- Rectangular Selection
- Selection
- Formatted Text

This video shows you how to manage the structure of XML documents with the XML Refactoring tool. To demonstrate this tool, this video presents a few of the pre-defined operations that are included in Oxygen.
- Rename Element
- Unwrap Element
- XML Refactoring
In this video demonstration, you will learn how to easily modify, delete, or wrap (with an element) content highlighted through an XPath expression or a Find operation.
- Manage highlighted content
- Modify all
- Remove all
- Surround all
This video demonstration shows you how to manage the dockable views, editors, and predefined layouts. It also shows you how to customize the toolbars and the appearance of the user interface.
- Dockable views
- Floating views
- Hideable views
- Configurable layout
- Theme
In this demonstration, you will see how Oxygen helps you to edit modular XML files that are referenced using external entities.
- XML Master Files
- XML Module Editing & Validation
- Search/Refactor Support for ID/IDREFs
- Module Connection Overview
- Rename or Move an XML Module
This demonstration shows you how to customize a DocBook XSL stylesheet in Oxygen.
- Publishing with a transformation scenario
- Customization layers
This demonstration shows you how to use a validation scenario in Oxygen for the validation of an individual module of a complex XML document in the context in which that module is used.
- Validation scenario
- XSLT transformation
- Multiple validation engines
- DocBook
This demonstration presents some of the features available in the OxygenGrid editing mode.
- Grid editing
- Format and Indent
This demonstration shows the folding support offered by Oxygen.
- Folding support
- Persistent folds
This demonstration presents the ID/IDREF support in Oxygen.
- ID/IDREF support for DTD / RelaxNG Schema / RelaxNG Schema compact syntax and XML Schema
This demonstration reviews the formatting options offered by Oxygen.
- Controlling the text formatting
- Indent size
- Line width
- Autodetect formatting options
This demonstration shows how optional content can be generated from XML Schema and DTD.
- Generate XML documents from schema or DTD
- Enabling optional content generation
This demonstration covers the use of code templates in Oxygen.
- Reuse document fragments (code templates)
- Code templates management

This demonstration teaches you how to configure a framework in Oxygen.
- Framework Configuration
- Document Type Association
- Document Templates
- NISO JATS
XSLT Editing
This video shows how you can improve the XSLT development work flow by offering fixes for errors that appear during development.
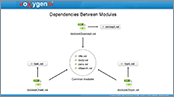
This demonstration shows the concept of "Master Files", which simplifies the configuration and development of XML projects.
- Master Files
This demonstration presents some of the XSLT refactoring actions available in Oxygen.
- XSLT Refactoring
- Reusable code snippets
- Refactoring actions
JSON
This video presents an overview of the visual editing support for JSON documents in Oxygen.
- Oxygen
- xml
- author
This video shows some of the useful tools and features that are provided in Oxygen to help you work with JSON documents.
- JSON Tools
- JSON Validation
- JSON Schema
- JSON
This demonstration shows several techniques and features for working with JSON documents in a more productive way.
- JSON Validation
- JSON Schema
- JSON
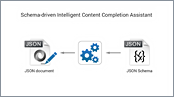
This video demonstration provides a brief overview of the JSON editing support in Oxygen after various improvements were implemented in version 21.0. The features shown in the video include the functionality of the Outline view, content completion assistance, associating a JSON Schema to a JSON document, defining code templates, and more.
- JSON
- JSON Schema
- JSON Content Completion
- JSON Outline
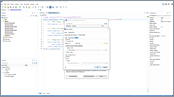
This video shows how to use XPath expressions to query JSON documents, how to transform JSON documents using XSLT, and how to query and transform JSON documents using XQuery.
- JSON
- JSON Transform
- JSON Query
- XSLT
- XPath
XML Development
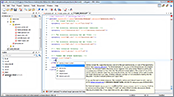
This video demonstration will guide you through the process of creating, editing, and running an Ant build file.
- Ant support
XSLT Transformations
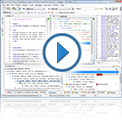
This video shows how the Oxygen XSLT/XQuery Profiler works.
- XSLT/XQuery Profiler
- XSLT/XQuery Debugger
- Invocation tree
- Hotspots
- Export to XML & HTML
This demonstration provides an example of using the XSLT Debugger.
- XSLT Debugger
- Conditional Breakpoints
- XWatch View
- Output Mapping Stack View
This demonstration provides a scenario based on a XSLT debugging session.
- XSLT Debugger
- Debugging scenario
- Transformer engines
Schema Editing
This video demonstrates how Schematron Quick Fixes can help you resolve errors in XML documents. It shows you how to apply these quick fixes in Oxygen and also explains some more advanced features, specifically for developers.
- Schematron
- Quick Fix
- SQF
This video demonstration walks you through the steps for creating a Schematron Document from scratch and presents helpful features, such as the validation support and the Content Completion Assistant.
- Content Completion Assistant
- Predefined Code Templates
- Progressive Validation
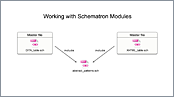
This video covers several Oxygen features that are useful for developing Schematron modules, the use of the Content Completion Assistant, Master Files support, and search and refactoring actions.
- Schematron Master Files Support
- Content Completion Assistant
- Search and Refactoring Actions
This demonstration highlights the XML Schema 1.1 features available in Oxygen.
- XML Schema 1.1
- Assertion
- Open content
- Type alternative
- XML Schema documentation
- Generate XML instance

This demonstration covers content topics that include developing an XML Schema in the Design mode from scratch, editing complex XML schemas, and generating schema documentation.
- Visual XML Schema editing
- Import schema modules
- Configure validation rule
- Search and refactoring actions
- Generate schema documentation
This demonstration presents the Palette editing view. It is designed to offer quick access to XML Schema components and it improves the usability of the XML Schema diagram builder, allowing you to drag components from the Palette view and drop them into the Design mode.
- Schema Palette
- XML Schema editing
- XML validation
This video shows how you can improve the schema development work flow using the Quick Assist actions set.
- XML Schema editing
- Quick Assist
- Resource Hierarchy
This video demonstration teaches you how to validate an XML document with a Schematron, or with an XML Schema/Relax NG Schema with embedded Schematron rules.
- Schematron support
- Relax NG schema
- ISO Schematron
XQuery Debugging
This demonstration shows the improved support for the MarkLogic database. The improvements include, among other things, remote debugging and XQuery editing, XQuery validation, and a XQuery builder that is designed specifically for improved productivity.
- Remote debugging and XQuery editing
- XQuery validation
- A new XQuery builder
This video presents the XQuery debugging capabilities in detail.
- XQuery debugger
- Saxon
- Profiling
WSDL Support
This video demonstration presents the WSDL editing support in Oxygen, showing you how to easily create a WSDL document, using the Content Completion Assistant, and the Outline view.
- Create new WSDL from scratch
- Validate WSDL file
- Content Completion
- WSDL Outline View

This video demonstrates the ability to edit modular WSDL files in Oxygen and the benefits of using the Master Files support when working with WSDL documents.
- Master Files
- Search and Refactoring Actions
- Quick Assist
SharePoint & WebDAV Support
This video demonstration highlights the resource browsing and filtering capabilities available when accessing a SharePoint repository with Oxygen.
- SharePoint
- Open URL dialog
- Filter/Sort resources
This video demonstrates the ability to connect to a repository located on a SharePoint server and how you can use SharePoint-specific actions when editing topics in a DITA Map.
- SharePoint
- Data Source Explorer
- Opening remote files
- Creating data source connections

This demonstration presents the WebDAV support in Oxygen.
- WebDAV
- Data Source Explorer
- Opening remote files
- Creating data source connections
XML & Relational Databases
This video presents the integration between Oxygen and an eXist database.
- eXist database
- XQuery
- Transformation scenario
Editing OOXML Documents

This video will show you how to easily export XML content from Oxygen to Microsoft Excel (or other spreadsheet applications) and how to import content from spreadsheet applications into an XML file in Oxygen.
- Generate MS Excel report (OOXML format)
- Extract data from database
Tools
This video presents the file comparison support that is integrated in the Eclipse distribution of Oxygen XML Editor.
- Oxygen
- xml
- author
- Compare
This video presents many of the specialized HTML5 features that are provided in Oxygen.
- HTML5
This demonstration offers an overview of the Oxygen publishing templates feature and shows you how to create a new template starting from an existing one, and how to customize various aspects of WebHelp and PDF output using CSS styling.
- Publishing Templates
- WebHelp Responsive
- Template
- opt

This demonstration shows you how to use the visual Author mode in the File Comparison tool.
- Comparing and Merging Files
- Visual Diff
- Visual Mode
This video presents Compare Directories Against a Base feature available in Oxygen XML suite of products. The feature helps you identify and merge changes between multiple modifications of the same directory structure.
- Merge
- Compare dirs
- Three way diff
- Compare
This video demonstration presents an overview of the WebHelp Responsive online help system.
- WebHelp Responsive
- Skin
- Templates
This demonstration will show you how the three-way comparison feature works in Oxygen and how you can use it with file versioning systems.
- Three way diff
- SVN
- SourceTree
- Git
- Compare
This video shows how to visually customize the look and feel of WebHelp output using the Skin Builder.
- Customize Webhelp Output
- Skin Builder
- Customize Theme

This demonstration shows how members of a documentation team can collaborate using Oxygen and Syncro SVN Client.
- Subversion
- Collaboration
- XML Authoring

This video demonstration presents the ability to generate cross-platform WebHelp systems for mobile devices and shows you how the output works on a tablet.
- Webhelp Mobile
- Online Documentation
- Single Source Publishing
This video demonstration presents the add-on deployment support that will allow plugins and frameworks to be automatically discovered and installed from a remote location.
- Add-on
- framework
- plugin
This demonstration presents the Feedback-Enabled WebHelp support offered by Oxygen.
- WebHelp
- Feedback-enabled
- DITA
- DocBook
This video offers an overview of the Oxygen XML Diff tool and its features.
- XML Diff & Merge
- Compare directories
- Compare files
- Compare
This video presents the basic functionality of the Syncro SVN Client.
- SVN repository
- Check Out
- Working Copy
- Automatic Refresh
- Synchronize with repository
- Mark as Merged
- Update
- Compare revisions
Webinars
Oxygen XML Editor 28

Discover how Oxygen XML Editor streamlines S1000D authoring with built-in support for editing, validation, visual authoring, templates, BREX handling, and Smart Paste.
In this webinar, you’ll see how teams can create, manage, and maintain Data Modules and Publication Modules more efficiently across Oxygen XML Editor Desktop, Web Author, the Eclipse plugin, and Content Fusion. The session will also highlight how AI-powered capabilities in Oxygen can assist authors, reduce repetitive work, and improve overall productivity.
Join us to learn how Oxygen reduces authoring friction and delivers a more consistent, efficient, and productive S1000D authoring experience.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
In this webinar, we’ll show you how two Oxygen XML Editor add-ons - Fluenta DITA Translation and Oxygen AI Translator - can work together to make translating DITA projects faster, easier, and more efficient.
The Fluenta DITA Translation add-on is designed to simplify DITA translation by generating a single, unified XLIFF file ready to be sent to your Language Service Provider (LSP).
Oxygen AI Translator complements this process by adding AI-powered translation capabilities for XLIFF-based projects, helping you accelerate translation without sacrificing quality.
Throughout this live session, we’ll walk you through practical, real-world translation workflows, including:
- How to structure and organize a DITA project for translation.
- How to use Fluenta DITA Translation to create and manage translation packages.
- How to leverage Oxygen AI Translator to generate translations quickly and efficiently.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

Dive into the world of vibe authoring and discover how Oxygen AI Positron 8.0 makes it more powerful and efficient than ever.
In this session, you’ll learn how Positron 8.0’s latest capabilities enable a richer, more context-aware collaboration with AI while you retain full editorial control and consistency. We’ll walk through real-world scenarios that illustrate how to embed your “vibe” into structured content using Positron’s new features.
This 1-hour live webinar will also introduce the brand-new Oxygen AI Translator - an AI-powered translation system built specifically for XLIFF workflows. It leverages Positron’s capabilities to deliver high-quality translations while preserving XML structure integrity, and includes built-in quality validation, translation memory support, and job-orchestration features.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

Join our product team and discover what’s new in version 28 of the Oxygen XML editing suite in this live overview and panel discussion!
We’ll highlight key authoring improvements, such as the new DITA Maps Manager welcome screen and quick find filter, smarter resource linking and integrity checks, and streamlined review workflows. You’ll also see how AI is more deeply integrated into authoring and automation.
Developers will learn about the enhanced XSLT and XQuery support, AI-driven autocompletion, improved comparison tools, and updated support for XProc 3.0 and 3.1.
For Web Author, we’ll showcase more efficient editing and reviewing (including searching in attribute values, resizing table columns with drag and drop, expanding large tables, as well as adding comments from the floating toolbar) alongside new AI improvements for your workflow, such as the updated chat input with the possibility to add attachments separately from the prompt text and chat context inspection.
Join us to see how version 28 advances the entire Oxygen XML ecosystem and to engage directly with the experts who build it!
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Oxygen XML Web Author 27

Oxygen AI Positron makes it easier than ever for subject matter experts (SMEs) to contribute well-structured content, helping to overcome the common challenges of creating properly structured documents.
Join our live webinar for an in-depth look at the newest enhancements to Oxygen AI Positron in Web Author and Content Fusion. This 1-hour live session will highlight how these latest AI-driven features can make your authoring and collaboration workflows smarter, faster, and more efficient.
The following topics will be covered:
- Attachments – Add files (Markdown, PDF, Word, PowerPoint documents) or screenshots to conversations for clearer context.
- Automatic Validation – AI-generated content is automatically checked and corrected to maintain valid documents.
- Persistent Chat, History, and Favorites – Continue discussions across sessions, access past conversations, and save useful prompts.
- Project-Level Custom Actions – Define actions that match project-specific workflows and apply them consistently.
- Models and Connectors – Work with a wider range of AI models and integrate with external services more easily.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Oxygen Positron 6

Discover how the latest release of the Oxygen AI Positron Assistant is transforming the way you create, validate, and manage intelligent content.
In this live webinar, we’ll walk you through the powerful new features introduced in version 6.0, designed to boost collaboration, enhance AI integration, and streamline your content workflows.
During this 45-minute live session, Sorin Carbunaru will address:
- Team Subscription Management – Easily manage team-wide subscriptions, making it simple to onboard users and allocate access across your organization.
- Automatic Validation and Correction of AI-Generated Content – Improve accuracy and ensure compliance with content standards.
- Rules Saved as Persistent Memories – Create smarter, more consistent editing environments by saving and reusing custom rules that evolve with your workflows.
- Enterprise AI Service Configuration via JSON – Easily set up and control how the AI service works across your organization, with options to automate the initial configuration and ensure consistent settings for all users.
We’ll also give you a sneak peek into what’s coming next for the Positron Assistant, with a glimpse at some of the exciting developments on our roadmap.
Don’t miss this opportunity to stay ahead of the AI curve!
- webinar editor author xml ai positron AI-Powered Writing
Oxygen Content Fusion 8

Join us for an in-depth look at the early-access Cloud version of Oxygen Content Fusion, designed to streamline collaborative technical documentation. We’ll highlight how it enhances workflows, from authoring and reviews to publication and delivery, within a secure, vendor-managed environment.
In this 1-hour live webinar, you’ll learn how Content Fusion Cloud uniquely enables you to:
- Work with projects, which provide an authoring workspace while ensuring controlled versioning and branching.
- Host and manage published output directly in the platform, making publication delivery frictionless and centralized.
- Integrate seamlessly with Oxygen XML Editor, gaining a smooth handoff between desktop authoring and cloud collaboration.
- Leverage Oxygen AI Positron services through the integration to refine content, generate variants, improve clarity, and accelerate topic development using AI assistance.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

Take your DITA content management to the next level with Oxygen Content Fusion. In this live session, you'll discover how Content Fusion goes beyond its original review use-case to provide a web-based DITA CMS providing structured content authoring, Git-based version control, AI-assisted refinement via Oxygen AI Positron, and publishing.
From authoring and managing deliverables to coordinating with stakeholders, Content Fusion simplifies every step of the content lifecycle—keeping your projects in sync and your team aligned.
We'll also showcase practical workflows you can start using right away, including:
- Documenting a new feature in Oxygen using a feature branch, submitting it for review, merging, and publishing
- Importing an existing project and applying a preconfigured publishing template
- Integrating Markdown-based topics in a DITA project
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

In today’s fast-paced technical landscape, subject matter experts (SMEs) are essential in ensuring that documentation is accurate, reliable, and free from critical errors. However, traditional review methods often result in inefficient workflows, version control headaches, and wasted resources.
This webinar will dive into how Oxygen Content Fusion can elevate your documentation review process, ensuring SMEs remain engaged, feedback is efficiently integrated, and your documentation reflects the highest technical standards.
Join us and discover how you can transform the documentation review process by:
- Streamlining Feedback: Consolidate inputs from all SMEs into a single, easy-to-manage document—eliminating multiple review cycles and duplicated feedback.
- Real-Time Collaboration: Enable simultaneous review, where feedback is gathered and addressed instantly, reducing delays and improving clarity.
- Centralized Management: Integrate directly with Oxygen XML Editor/Author to manage review tasks from within your familiar editing environment, reducing the need to juggle multiple tools.
- Enhanced Task and Version Control: Utilize advanced task management and robust version control tools to merge changes seamlessly, ensuring that every contribution is accurately captured without compromising document integrity.
- Improved Accessibility: Allow reviewers to participate via a web browser, making the process accessible regardless of their location or technical skill level.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

Join the Oxygen XML team for an insightful webinar on overcoming common Git and DITA challenges with the help of Oxygen Content Fusion. Whether you're dealing with review bottlenecks, publishing hurdles, or translation complexities, this session will provide practical solutions to streamline your workflow.
During this 1-hour live event, the following topics will be covered:
- Review from Subject Matter Experts (SME) using Content Fusion – How to simplify collaboration and feedback collection.
- Publishing workflows – Learn to optimize your publishing process.
- Link management – Discover how to maintain and troubleshoot DITA links efficiently.
- Translations – Leverage built-in tools to easily manage multilingual content.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Oxygen XML Editor 27

Join us for an insightful webinar exploring how the latest capabilities of the Oxygen XML Positron Assistant can elevate your documentation process. Learn how to integrate powerful AI features or leverage built-in AI-driven actions to efficiently manage your document content and project structure.
We’ll showcase practical use cases where AI takes the lead, including:
- Identifying reusable components
- Creating new files directly within your project
- Automatically adding topic references to your DITA map
- Leveraging RAG (Retrieval-Augmented Generation) over published content
- Resolving validation issues
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Unlock the full potential of JSON documents with Oxygen! This live event demonstrates how to efficiently transform JSON into XML, HTML, or other formats using powerful XSLT and XQuery processing tools. Dive into advanced techniques for querying JSON data effectively with XPath expressions or XQuery.
In this session, you will learn from the following topics explored by Octavian Nadolu:
- JSON Transformation with XSLT: Seamlessly convert JSON documents into various formats.
- JSON Querying with XQuery: Extract and manipulate JSON data with precision.
- Batch Processing: Perform transformations and queries on multiple documents directly from your project.
- XPath for JSON: Leverage XPath expressions for intuitive and efficient JSON querying.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

Join us for an engaging webinar with Octavian Nadolu, where you'll uncover how cutting-edge AI features can transform your XML development workflow.
Don't miss this opportunity to see how AI can revolutionize your approach to XML development and content management by gaining valuable insights into:
- AI-Enhanced Development Tools: Explore integrated AI capabilities for XSLT, XQuery, Schematron, XSD, and JSON Schema to boost efficiency.
- Custom AI Actions: Learn how to design and implement AI-driven actions tailored to your specific development needs.
- AI in Schematron: Discover how to leverage AI for advanced content verification and automated correction.
- AI with XSLT: Master the use of AI to streamline the management and processing of complex content.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

Discover how to streamline error resolution with the latest automation features in Oxygen XML Editor!
This webinar introduces you to the Apply All Default Quick Fix Proposals tool, which enables you to effortlessly apply all suggested quick fixes across one or multiple resources simultaneously. Designed to address validation errors efficiently, this feature automatically executes quick fixes in bulk, ensuring a seamless error resolution process within a specified scope.
Join Octavian Nadolu as he demonstrates how this powerful tool can save you time and simplify your workflow. In this session, you'll learn to:
- Define and Customize Quick Fixes: Tailor quick fixes to meet the specific needs of your project.
- Resolve Issues Efficiently: Address all validation errors within a document with ease.
- Fix Errors from Anywhere: Tackle issues directly from the Project view or DITA Maps Manager.
- Leverage AI-Powered Batch Processing: Utilize advanced AI Quick Fixes to streamline error resolution and enhance productivity.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

These past weeks saw the release of version 27 for the industry-leading XML suite of products: Oxygen XML Editor, Author, Developer, Web Author, Publishing Engine, WebHelp, PDF Chemistry, Scripting, and JSON Editor.
To see how this release builds upon the always expanding suite of our products, join us on the 18th of December, for an overview and discussion that will allow you to engage with the creative people behind Oxygen.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Oxygen Feedback 5

In the second part of the "Oxygen XML & AI" webinar series we continue to explore the AI tools available to enhance the Oxygen experience, this time taking a look at the ones designed to revolutionize the way your audience interacts with your technical documentation.
In this live event, you will get to discover how Oxygen Feedback 5.0 leverages the new AI Assistant feature to provide instant, context-aware answers, and see the AI-Enhanced Search Summary in action, offering smarter and more relevant search results. Alin Balasa will demonstrate step-by-step how to seamlessly integrate these powerful tools into your WebHelp output, optimizing both content discovery and user engagement.
Join us so you can unlock the potential of AI in your documentation workflows and empower your users to navigate and interact with your published content like never before.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Oxygen XML Editor 26

We live in the age of "fast": fast internet, fast transportation, fast-spreading news. While it's important to slow down in some areas of our lives, speeding up our 9-to-5 work is beneficial, especially when it doesn't require us to work harder.
With our two-part webinar series, "Oxygen XML & AI," we want to show you the ways in which the AI tools that we put at your disposal enrich your Oxygen experience.
In this first webinar, Sorin Carbunaru will focus on the Oxygen AI Positron Assistant plugin, a productivity-increasing and efficiency-boosting tool that technical writers can use along with Oxygen XML Editor in their day-to-day work.
Join us and discover how you can work faster in Oxygen with the help of AI, while also exploring the latest features and improvements brought by the newest version of Oxygen AI Positron Assistant (3.0) , including:
- Retrieval-Augmented Generation (RAG)
- The new AI Positron widget in the Author page
- AI-powered actions specific to working with DITA XML documents
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

Over the past year, AI services such as ChatGPT have established themselves as valuable tools for content creation and review. However, each passing month brings new advancements. Among these, OpenAI's GPT4 with Vision, which can understand images, creates new opportunities for workflows and scenarios at the early stages of content development.
In this one-hour webinar, we will delve into how AI can transform content creation by exploring the Oxygen AI Positron add-on as an invaluable writing companion by focusing on the following topics:
- The latest developments in the release of Oxygen AI Positron 2.0.
- Techniques for drafting documentation that integrates both content and images.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

Join us for an exciting webinar as we unveil the latest enhancements in Oxygen XML Web Author 26.1! We're thrilled to showcase a range of new features designed to enhance your authoring experience. Here's a sneak peek at some of the highlights we'll be covering:
- User Authentication: Enable secure access to Web Author, adding an extra layer of protection to content access and editing.
- AI Positron Assistant: Experience the power of artificial intelligence with our enhanced Positron Assistant Side View.
- DITA Profiling improvements: Easily manage and control your content by selectively showing or hiding specific sections based on DITAVAL filters, ensuring that only relevant content is displayed.
- DITA Project File and Context Filtering: Set a DITA project file and context to filter document content.
- CSS Inspector Pane: Check and fine-tune the styling and formatting of your content with the new CSS Inspector Pane.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
If you are interested in exploring the latest features in Oxygen that enhance the comparison support, join us for a webinar that will focus on some of the new and exciting capabilities of the Merge Documents with Change Tracking Highlights and Merge Directories with Change Tracking Highlights.
During the session, we will cover the following topics:
- An overview of the comparison support in Oxygen, giving you a comprehensive understanding of the various options available for comparing files.
- A deep dive into the feature of Merge Documents with Change Tracking Highlights, as we demonstrate how you can merge two XML files while saving the visual comparison results as a separate document with tracked changes.
- The exploration of the Merge Directories with Change Tracking Highlights tool to show you how easy it is to merge two directories based on a 2-way mode comparison and how you can conveniently review and manage the changes in the resulting document.
- A demonstration on how to generate an HTML or PDF report with the comparison result, providing a comprehensive overview of the changes made.
- If you're interested in automating these processes, we will also demonstrate how to use the Merge Files/Directories with Change Tracking Highlights from scripting.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

In this 1-hour webinar, we will delve into the robustness of Oxygen's YAML support and showcase the exciting new features introduced in Oxygen 26.
During the webinar, we will explore a range of features and improvements that have been implemented, offering you a comprehensive understanding of Oxygen's capabilities when working with YAML documents.
Some of the topics of the webinar include:
- How to effortlessly create YAML documents based on a schema, ensuring consistency and adherence to standards.
- The way Oxygen enables you to check if your YAML documents are well-formed, avoiding potential syntax errors.
- Exploring the powerful validation capabilities of Oxygen, which allow you to validate YAML documents using JSON Schema, giving you confidence in the integrity of your data.
- The intelligent content completion in YAML documents and how it leverages the schema to enhance your productivity.
- How to make your YAML documents visually appealing and easy to navigate.
- Gaining insights into the seamless conversion capabilities of Oxygen, allowing you to transform YAML into other popular formats such as JSON and XML.
- How Oxygen effectively supports OpenAPI and AsyncAPI specifications in YAML format, opening up new possibilities for working with APIs.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

Whether you're a seasoned developer looking for a specialized tool or just starting out with JSON, the brand new Oxygen JSON Editor is designed to meet all your JSON editing needs. This comprehensive solution offers a range of powerful features that will enhance your productivity and streamline your JSON editing processes.
Join this 1-hour live event to discover how the Oxygen JSON Editor can revolutionize your JSON development workflow as we will explore its key features:
- Editing JSON and JSON Schema documents with various editing modes including Text, Grid, and Author.
- A dedicated Design mode that enables you to easily create and modify JSON Schema files ensuring accuracy and structural integrity of your JSON data.
- The intuitive interface that simplifies navigation and comprehension of complex JSON documents.
- The various tools that can assist you with converting, generating, and documenting your JSON, JSON Schema, YAML, and OpenAPI documents.
- A wide range of supported technologies such as YAML, HTML, CSS, LESS, Python, Text, Shell, and more.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Over the past few months, the introduction of OpenAI's ChatGPT has opened up a plethora of exciting opportunities for leveraging AI in technical content creation. In this presentation, we will delve into how AI can transform content creation by exploring the Oxygen AI Positron add-on as an invaluable writing companion.
During this 1-hour live webinar, we will cover the following topics:
- Demonstrating various scenarios and workflows made possible by the Oxygen AI Positron Assistant.
- Exploring the wide range of available actions and showcasing how these actions can be invoked, refined, and previewed using the visual diff feature to easily understand the document changes.
- Showcasing how users can define and share their own AI processing, allowing for greater customization and flexibility.
- Guiding participants on how to improve the AI's understanding and accuracy by providing a collection of examples in the editing area, helping the AI to consistently provide the correct answers.
- Introducing Oxygen AI Positron's availability in the Web Author platform.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Oxygen Feedback 4

Join us for an exciting webinar as we dive deep into the new features of Oxygen Feedback 4.0!
In 1 hour, we'll explore features such as faceted search, advanced query capabilities, content labeling, and semantic search.
To elevate your website's search functionality and deliver an exceptional user experience with Oxygen Feedback 4.0, we'll uncover the following crucial aspects:
- How to seamlessly integrate Oxygen Feedback into your WebHelp Responsive output.
- Enabling content indexing and empowering efficient server-side search functionality.
- Leveraging the power of a DITA Classification Map to enhance your documentation with customizable facets.
- Harnessing the potential of faceted search to refine and pinpoint your search results effectively.
- Enhancing your DITA topics by adding custom labels.
- The shared labels and how they can facilitate your search for various topics.
- Mastering the art of crafting advanced search queries to fine-tune and optimize your search results.
- Elevating your WebHelp output with the activation of semantic search, delivering more contextually relevant results.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Oxygen XML Web Author 26

Are you looking to integrate Oxygen XML Web Author into your existing XML workflow?
If the answer is a resounding YES, we invite you to join us for an insightful webinar where we'll walk you through the initial steps to maximize the potential of Oxygen XML Web Author within your workflow. During this session, you'll gain valuable insights and practical guidance on how to:
- Connect Oxygen XML Web Author to your file storage system.
- Customize the editor to render your XML documents in a WYSIWYG mode.
- Create actions and help users easily edit your documents.
- Create custom validation rules to ensure the integrity and quality of your XML documents.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing

During this webinar, you will discover the new features included in the latest releases of the Oxygen XML Web Author, with a special focus on version 26.0, related to security, concurrent editing, profiling attributes and much more.
You'll also see how the new AI Positron Assistant side-view provides you with various ways to use ChatGPT while editing or reviewing content. This tool offers a comprehensive interface for AI actions and options, empowering you to leverage the full capabilities of AI technology, thus enhancing your productivity. It allows you to receive helpful hints for your next writing steps, enhance the readability of your content, correct grammar errors, generate index terms, translate content, create marketing-related material, or even restructure your entire document.
Here are some features that will be presented during this event:
- Using the Shared Editing Session feature in a two-servers high availability Web Author deployment.
- The new security options available in Administration page.
- Utilizing the AI Positron Assistant Side View.
- Editing profiling attributes in DITA with ease.
- Efficiently using and editing Mermaid diagrams.
- webinar editor author xml html5 json schema markdown web author content fusion feedback publish engine ai positron AI-Powered Writing
Oxygen Content Fusion 6

With the release of the Beta version of Oxygen Content Fusion 6.0, we aimed to enhance the DITA documentation review and publishing processes for the advanced online collaboration platform.
As we approach the full release, planned for October, we highly value your feedback and invite you to actively participate in shaping the final version of Oxygen Content Fusion 6.0. Your insights will play a crucial role in refining this cutting-edge collaboration platform. Thus, we invite you to join us for an exclusive webinar where we will showcase the significant improvements and features of Oxygen Content Fusion 6.0 Beta.
The topics of this webinar will focus on the following features and improvements of Oxygen Content Fusion 6.0 Beta:
- Projects: Seamlessly integrate with Git repositories to track reviewers feedback on dedicated branches for each review task.
- Enhanced Publishing Capabilities: Effortlessly generate WebHelp or PDF outputs with new publishing features. Customize the output via the integrated Oxygen Styles Basket visual customization tool, providing easy and flexible customization options.
- Improved Review Workflow: Review task owners now have the ability to close a review, allowing time to address feedback effectively.
- Optimized User Experience: Alongside the introduction of numerous new features, Oxygen Content Fusion's user interface has undergone enhancements, now offering an improved and refreshed look and feel.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
Oxygen Feedback 3

The latest release of Oxygen Feedback version 3.0 brought some exciting new enhancements for the modern comment management platform, including the implementation of content indexing and search functionality. This webinar aims to provide details about the various features that were implemented for those who want to enable content indexing and search functionality, as well as information about other new features that were implemented in version 3.0.
Some of the things that you can expect to be covered in this webinar include:
- Information about the new Content Indexing feature.
- Details about the automatic re-indexing functionality.
- Ability to choose from various different languages for the indexing process.
- Searching the WebHelp Responsive output.
- An overview of various other new features that were added in version 3.0.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
Oxygen XML Editor 25

The journey into the world of AI continues by exploring its application in conjunction with Schematron and Schematron Quick Fix (SQF) for content verification and correction. In this webinar, we aim to offer a comprehensive overview of AI, highlight the potential advantages it brings, and shed light on the challenges we encounter when utilizing AI for these purposes.
Don't miss this opportunity to gain valuable insights into the intersection of AI and content validation by exploring topics such as:
- Artificial Intelligence (AI)
- OpenAI/Generative Pre-trained Transformer
- Schematron and Schematron Quick Fixes (SQF)
- Implementing AI in Schematron and SQF
- Examples of AI-driven Schematron and SQF Solutions
- Benefits of Using AI in Schematron and SQF
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

In recent months, AI technology has advanced to the point where it is now applicable in a wide range of real-world situations. However, the AI-generated content is not always accurate, making it challenging to introduce this technology to end users. On the other hand, this is precisely why technical writers are an excellent fit for AI since they can serve as a mediator between the AI and the end users, using it to boost their productivity while ensuring the content that they deliver is accurate.
Oxygen AI Positron Assistant is a new plugin for the Oxygen XML tools that connects to the Open AI Chat GPT engine to introduce AI technology to support technical writing operations. To keep authors in control, the workflows are optimized to include preview of proposed AI changes and the possibility to refine the results. Custom AI interactions are also possible and you can reuse them easily with the save as favorites support.
During this 1-hour live webinar, we will:
- Showcase the use cases that the Oxygen AI Positron Assistant enables.
- Explore the available actions and see how they can be invoked, refined, and preview their results in the visual diff to understand the document changes.
- See how you can define your own AI processing and mark them as favorites.
- Highlight the tasks best suited for AI technology use.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

A traditional tutorial implies a set of written instructions that the users must follow. Oxygen takes the concept one step further. With our Live Tutorials add-on, the tutorial is embedded within the application itself. The samples for each step are opened automatically, hints are available on request and the mission success is detected automatically.
During this live webinar, we will explore:
- The built-in DITA interactive tutorials.
- How to create new tutorials and journeys.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
Docs as code is a philosophy according to which you should write documentation using the same tools and workflows that software developers use to write code. But it's not so much about the tools, as it is about the workflows and practices involved, such as continuous integration or version control.
During this event, we will have a look at such a setup using open-source tools and standards that include:
- DITA, as the plain text format we'll use, because it fits the profile and brings additional benefits to the mix: semantics, content reuse, publishing options.
- Storage and version control using Git (trunk-based development).
- Project validation in continuous integration pipelines.
- Translation workflows based on Fluenta:
- Creating and sharing a Fluenta configuration.
- Sending the DITA project to the translation service provider as XLIFF.
- Generating the translated version of the DITA project once the XLIFF returns from translation.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

During this webinar, you will discover the new features included in the latest release of the Oxygen XML Web Author related to DITA Map files editing, as well as other general enhancements that will improve your editing experience, regardless of the edited document type.
You'll also witness firsthand a Git workflow demonstration that allows Subject Matter Experts (SMEs) to contribute content in a Git repository without having to solve conflicts and without them having to learn and remember DITA details or a specific topics structure. SMEs will seamlessly concurrently edit all the DITA topics by opening just the DITA Map that shows all topics expanded, also having the possibility to easily get around, sort topics, and add new ones.
Here are some features that will be presented during this event:
- Conflict-free Git workflow with concurrent editing for SMEs with no DITA knowledge required
- How to insert new DITA topics with inline actions
- How to navigate and edit a DITA Map with Outline pane
- The Smart Paste improvements
- The new actions from the Floating Toolbar
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
The PDF customization journey isn't finished just yet! Have you ever thought about controlling the change bars display, modifying your PDF viewer behavior or centering and rotating your tables?
You're in luck because we created for you a webinar in which the following topics will be covered in great detail:
- Advanced images display
- Advanced tables display
- Change bars customization
- PDF Viewer control
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

With the latest release of the Oxygen suite of products, additional support was developed for validating XML and JSON files via Oxygen XML Scripting.
This webinar will cover details about this newly implemented validation scripting support, as well as showing examples of how to use it efficiently. You will learn how to validate files or directories from a command line interface. You can check that your documents are valid from an integration server and you can generate reports in several formats (text, XML, JSON, or an HTML visual format). We won’t be stopping there, as we will also be looking at how you can use transformation or comparison scripts.
During this 1-hour live event, we will focus on showing you the following:
- How to use the Validation command-line script
- How to validate against a specific schema file
- How to validate using the default Oxygen validation scenarios
- How to use validation scenario from either a scenarios file or a project file
- How to generate the validation results in various formats (YAML, JSON, XML, HTML)
- How to run validation on an continuous integration server CI/CD
- How to use the Transformation command-line script
- How to use the Comparison/Merge command-line script
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

OpenAPI is a community-driven open specification that defines a language-agnostic interface used to describe, produce, consume, and visualize RESTful APIs and web services.
AsyncAPI started as an adaptation of the OpenAPI specification, used for describing asynchronous messaging APIs.
OpenAPI/AsyncAPI documents describe the API (or its elements) and are represented in either YAML or JSON formats.
During this live webinar, you will discover the support offered in Oxygen to create, edit, and validate OpenAPI/AsyncAPI documents as well as how to test, and generate documentation for OpenAPI documents. By joining this live event, you will get the chance to learn the following:
- How to create OpenAPI/AsyncAPI documents
- How to edit and validate OpenAPI/AsyncAPI documents
- How edit OpenAPI/AsyncAPI documentation in Author mode
- How to generate documentation for OpenAPI components in HTML format
- How to test an OpenAPI, execute API requests, and validate responses
- How to create and run test scenarios
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

This webinar will present various powerful tools that are provided in Oxygen that allow you to design, develop, and edit JSON Schemas. We will focus on presenting features ranging from the new intuitive and expressive visual schema Design mode to the JSON Schema documentation generator that includes diagram images for each component.
During this live webinar, you will get the chance to learn and experience an in-depth look at all of these features:
- How to create JSON schemas
- How to use the JSON Schema Design mode
- What changes the JSON Schema version 2020-12 brings to Oxygen
- How to edit and validate JSON Schema version 2020-12
- How to use the new refactoring actions
- How to visualize and edit complex JSON Schemas
- How to generate documentation for JSON Schema
- How to use OpenAPI with JSON Schema
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

Some documentation projects require a mix of document formats (e.g. DITA for content, Markdown for release notes, JSON for API documentation). In this webinar, we will demonstrate how you can integrate OpenAPI, Word, Markdown, HTML, and Excel content into your DITA documentation using Oxygen tools and features.
We will cover the following subjects:
- Referencing content from various types of non-DITA resources directly in DITA documents
- Dynamically converting various types of non-DITA resources to DITA while publishing
- Converting various formats into DITA and integrating them into the project
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
Oxygen XML Editor 24
We all know that the road to becoming advanced in a specific subject is a long and tedious one. But with our help, it doesn’t need to be that difficult anymore!
Your journey into defining the look and format of your PDF documents with the use of CSS continues with another extensive tutorial, this time dedicated to adding custom fonts in your CSS.
After this webinar, you will have all the tools needed to:
- Use System Fonts and WebFonts
- Import and use font files
- Declare fallback fonts
- Set fonts for page-margin boxes.
- Use Oxygen Styles Basket to define fonts
- Create an accessible PDF (PDF/UA)
- Use different fonts based on the language used
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

OpenAPI is a community-driven open specification that defines a language-agnostic interface used to describe, produce, consume, and visualize RESTful APIs and web services. OpenAPI documents describe the API (or its elements) and are represented in either YAML or JSON formats.
During this live webinar, you will discover the support offered in Oxygen for OpenAPI documents as well as how to create, edit, test, and generate documentation for OpenAPI documents. By joining this live event, you will get the chance to learn the following:
- How to edit OpenAPI documents in the Oxygen Text mode.
- How to use OpenAPI documents in Author mode - you have access to some form controls, collapsible sections, and other features that help you visualize and edit these types of documents.
- How to test an OpenAPI, execute API requests, and validate responses on the fly to ensure that they work as expected.
- How to generate documentation for OpenAPI components in HTML format, including comprehensive annotations and cross-references.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

The need to customize the appearance of published documentation is something that is being addressed constantly by our users. As a solution, Oxygen WebHelp offers a predefined set of layouts and styles, resulting in several different customization methods or combination of methods.
To get you accustomed to these options, this webinar will walk you through several techniques available for customizing the WebHelp Responsive output.
By joining this live event, you will get the chance to learn the following:
- What are the page types available and their components
- What is the Publishing Template – its purpose, structure, and resources
- Using CSS to change the layout and styles of your output
- Inserting additional HTML content
- How to insert dynamic content using WebHelp Macros
- Adding new functionalities using JavaScript
- How to copy additional resources in the output folder
- Modifying the page structure using XSLT
- Various customization examples
- webinar editor developer webhelp html5 publishing

Oxygen XML Editor provides a powerful and expressive visual schema diagram editor (Design mode) for editing JSON Schemas. The structure of the diagram editor is designed to be intuitive and easy to use.
By joining this live webinar, you will get to see how the Design mode can help both content authors who want to visualize or understand a schema and schema designers who develop complex schemas. You will also get the chance to learn:
- How to create JSON schemas from scratch
- How to use the new Pallet view to add new components
- How to use the drag-and-drop support to design your JSON Schema
- How to use refactoring actions
- How to visualize and edit complex JSON Schemas
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
You have now started your journey through DITA to PDF customization, but there is still a long way to go.
In Part 1 – Page Definitions, Cover Page and PDF Metadata, you got to learn how to customize your PDF publications using CSS and make them compliant with all your company documents.
Now, it’s time to move on and learn some great new tips and tricks about the PDF page layout. Join us and, at the end of this course, you will be able to:
- Create a personalized front and back-matter
- Use a Table of Contents and a list of Tables/Figures
- Define custom page-breaks
- Change the page layout
- Use custom PDF bookmarks
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

If you are planning to generate nice-looking documents for your company or just as personal projects but the simple mention of CSS makes you uneasy, don’t worry! The Oxygen Styles Basket is here to help you!
In this webinar, you will get to see what exactly is the Oxygen Styles Basket, how it works, and how you can use it to create a customization that works for both your PDF and WebHelp outputs.
After this course you will be able to:
- Define your project/company branding
- Set different styles for your publication content
- Define a PDF cover, global numbering scheme, etc.
- Customize a WebHelp layout
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

The already extensive support Oxygen offers for technical authoring can be further expanded with a variety of easy to install add-ons!
This webinar aims to take a deeper look at some of the most popular add-ons that are available and at the types of benefits they provide, how easy it is to install them, as well as offering some ideas for how they can be integrated into your particular authoring workflow.
The add-ons that will be featured in this webinar include:
- The Git Client add-on that contributes a Git client directly in the Oxygen interface.
- The DITA Outgoing References add-on that contributes a side view where you can see all the outgoing references for the current topic.
- The Terminology Checker add-on that highlights matched terms in the Author visual editing mode.
- The Translator Helper add-on that translates content using Google Translate or DeepL Translator to various languages.
- The Writer Helper add-on that helps with the review process, finding similar content, reads content with an operating system specific narrator, and provides Oxygen productivity tips.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

From experience, most companies do not start new DITA-based projects from scratch. They already have the content written in various other formats and they need that content converted to DITA. But once the content is converted, there is still work to be done. It also needs to be refactored to respect various DITA best practices.
To show you how this process can be made as simple as possible, in this webinar, we will cover the following topics:
- How to use the batch documents converter and smart paste for converting content
- How to use the Main Files Support for refactoring across the entire project
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

With the latest release of the Oxygen suite of products, additional support was developed for Oxygen XML Scripting in order to compare and merge files or directories.
In this webinar we will cover in detail this newly implemented scripting support, as well as showing you examples on how to use it efficiently. We won’t be stopping here, as we will also be taking a look at how you can integrate it with Oxygen XML Editor.
During this 1-hour live event, we will focus on showing you the following:
- The Compare and Merge Files Command-Line Script - used to compare and merge files and get the comparison results in various formats (YAML, JSON, XML, HTML).
- The Compare and Merge Directories Command-Line Script - with many options to choose from, such as the comparison mode (content, binary, timestamp), the algorithm to be used for the comparison, the "strength" of the comparison algorithm, various "include/exclude" type file filters, various "ignore" type options to refine the comparison results.
- Generating File or Directory Comparison HTML Reports - the support to save the comparison made with Oxygen XML Editor in HTML format.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

Oxygen XML Editor provides the ability to organize your DITA resources in projects. The DITA Sample Project is a best practice example that shows how DITA content can be organized to provide a scalable and flexible project structure.
With this in mind, during the course of this extensive online event, we will go over:
- the DITA Project structure
- using the Main files support to rename or move DITA resources
- creating a unified editing experience through project level settings
- spell check and terminology check project settings
- sharing a framework customization in the project
- sharing a publishing template in the project
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

Comparing documents and merging them is one of the most common parts of documentation workflows, for any set of evolving documents, whether it is for a newer version of a product or a simple document that goes through an improvement process.
The possibility to compare and merge documents in a browser allows reviewers or other stakeholders to see what was changed without the headache of needing to install a separate tool. Their productivity can further be improved by sharing a link that opens the file comparison tool with the changes already being highlighted.
With this in mind, this live webinar will get you accustomed to this more efficient method by showing you:
- Where does it fit in Oxygen’s internal workflow and how it is being used by our team.
- What is the 3-way merge and in what cases you can benefit from it.
- How to resolve the conflicts encountered when multiple users edit the same file.
- How to integrate the file comparison tool in a CMS to create a history view.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

To celebrate the release of version 24.0 of the Oxygen XML suite of products, a brand-new series of webinars have been created to shed light on the interesting new features and updates implemented in this latest version! Every Wednesday, Oxygen XML will host weekly live events where you can learn great insights from some of the most experienced people in the Tech Comm industry.
The series will start with a webinar in which we will show you how Oxygen now offers even more powerful tools that allow you to design, develop, and edit JSON Schemas. We will be focusing on presenting features ranging from the new intuitive and expressive visual schema Design mode, all the way up to the JSON Schema documentation generator that includes diagram images for each component.
During this live webinar, you will get the chance to take an in-depth look at all of these features, as well as learn:
- How to create JSON Schemas from scratch
- How to visualize and edit complex JSON Schemas
- How to generate JSON Schema documentation
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
Oxygen Feedback 2

With the release of Oxygen Feedback version 2.0, we created this immersive live event where you will get the chance to take a deeper look at the latest features implemented in our web-based commenting platform. Also, we will showcase the use of Feedback in conjunction with Oxygen XML Editor so you can learn how to continuously improve your online documentation based on your subject matter experts (SMEs) and community feedback.
This webinar will cover the following topics:
- Integrating Oxygen Feedback in your online documentation
- Receiving feedback from your SMEs and end-users
- Feedback moderation
- User roles and user management (promote/demote users)
- Usage statistics
- Oxygen integration - Easily update your content by accessing the comments stream directly in Oxygen
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
Oxygen XML Editor 23
With this fourth episode of our Transforming XML and HTML documents to PDF using CSS webinar series, the journey is coming to an end.
Now you're ready to tackle PDF publishing on your own. Here comes the last tutorial explaining how CSS can be your best asset for PDF publishing. And this time, we will explore some advanced features, such as:
- Hyphenation
- PDF Bookmarks (Level, Text)
- Metadata (Title, Author)
- Text extraction: the oxy_xpath function
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

A framework refers to a package that contains resources and configuration information to provide ready-to-use support for an XML vocabulary or document type.
Starting recently, a framework can be created using a special XML descriptor file, either from scratch or by extending an existing built-in framework (such as DITA or DocBook) and then making modifications to it. During this event, we will take an extensive look at this specific method by covering topics, such as:
- What benefits this new approach brings when compared with creating a framework in GUI.
- Exploring various use cases and implement them though the script.
- How to extend existing built-in or custom frameworks.
- What deployment options are available
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

We all like custom products and most of the time we invest extra time and energy into customizing our tools to better fit our specific needs and preferences.
In this fourth episode of our Working with DITA in Oxygen series, we will explore several ways of customizing the DITA editing experience according to your desires. This webinar will cover the customization of:
- Author actions - edit existing actions, remove actions or add new ones. Add actions to the main toolbar, the contextual menu, or the content completion window.
- The Author-mode rendering - tailor the visuals of the editing experience using CSS and add in-place actions directly in the Author page.
- Document validation - create new validation rules and provide quick fixes using Schematron.
- The content-completion assistant - automatically insert or reject elements, attributes, and values.
- New document templates - add prefixes or suffixes to the names of your new documents, customize the template icons, mark templates as popular
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
We all know that the road to becoming advanced in a specific subject is a long one. But it doesn’t need to be difficult!
Your journey into defining the look and format of your documents with the use of CSS continues with another extensive tutorial, this time dedicated to the global page layout. This means that during this event, you will learn how to create and control PDF pages directly from CSS. To achieve this ability, we will focus on the following subjects:
- @page CSS at-rule
- Page-margin boxes
- Page-selectors (default, front-page, etc.)
- Page orientation
- Column-count
- Page-breaks
- Odd and even pages
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
 01:54:48
01:54:48Spring arrived with a fresh new version for the Oxygen XML suite of products!
Version 23.1 of the industry-leading XML editing suite of products, Oxygen XML Editor, Author, Developer, Web Author, WebHelp, PDF Chemistry, and Oxygen Publishing Engine was released along with version 1.4 of the Oxygen Feedback comment management platform, and version 4.0 of the Oxygen Content Fusion collaboration platform.
To see how this release builds upon the always expanding suite of our products, we invite you to join us for an overview and discussion that will allow you to engage with the creative people behind Oxygen. Find out first-hand how you can benefit from features like:
- Concurrent editing and reviewing in Oxygen Content Fusion for streamlining your team's collaboration process.
- The ability to ignore validation problems using Quick Fix actions to filter errors and warnings wherever they are presented.
- The new Block-Level Comments functionality in Oxygen Feedback allows your users to add and manage comments contextually at a specific location within the WebHelp page.
- Oxygen Styles Basket, the free web-based visual tool that helps you fine-tune the CSS file that is used to customize PDF or WebHelp output by picking and mixing aspects from galleries.
The panel will bring together George Bina, Alexandru Jitianu, Octavian Nadolu, Cristi Talau, Alin Balasa, and Julien Lacour.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

If you watched our previous webinar on CSS customization and you want to continue your journey into defining the look and format of your documents, here is the second part!
In this webinar, you will learn some more advanced CSS properties and you will apply them on more complex elements:
- CSS combinators
- ::before and ::after pseudo elements
- Lists (ordered and unordered)
- Tables with their caption, header, and footer
- Images (resolution, size, url)
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

If becoming advanced in profiling and reusing DITA content is one of your new year's resolutions, then you're in luck! In this third webinar about working with DITA in Oxygen, we will help you achieve just that.
This webinar will cover more advanced DITA concepts, such as:
- Conref ranges - easily create content references to ranges of adjacent (sibling) elements.
- Conref push - an alternate way of creating content references, by injecting element values from the source element into a topic where it is to be re-used.
- Subject scheme maps - create custom controlled values and manage metadata attribute values for an organization or a project without having to write a DITA specialization.
- Profiling attribute groups - used to support situations where an attribute applies to multiple specialized subcategories.
- Key scopes - specify different sets of key definitions for different map branches.
- Branch filtering - set filtering conditions for specific branches of a map.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

Anyone can contribute to the technical documentation with the proper collaboration tools!
Content Fusion is a platform for all, not just for technical writers. You will see how it can positively impact each person involved in the technical documentation process:
- technical writers have full control over the content, they are the gate keepers of the documentation source.
- subject matter experts can create and push documentation drafts to technical writers
- users can propose changes just by following a link in the published output
Along with the presented use-cases, this session will highlight also DITA-specific features as well as some of the new additions to Content Fusion 4, in particular the concurrent editing support, allowing unrestricted access to edited files.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine
You want to publish your DITA books and maps in PDF but you are struggling with the process? Be assured that we understand how hard it is to be a novice.
In this webinar, we will teach you how to customize your PDF publications using CSS and make them compliant with all your company documents.
At the end of this crash-course, you will be able to:
- Define specific pages (frontmatter/backmatter, chapters, indexes, etc.)
- Set page sizes and page margins
- Fix content in headers/footers
- Create a cover page with little to no effort
- Add metadata into the final PDF
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

DITA content can be published to modern WebHelp Responsive online help format based on HTML5 featuring indexing and search, breadcrumb navigation, table of contents, responsive adaptive layout, and accessible content.
In this webinar, we will take an in-depth look at the WebHelp Responsive output and at the process that allows you to update content continuously by embedding a commenting component to collect your customers’ feedback.
Some of the topics covered in this webinar will include:
- How to publish DITA content to WebHelp Responsive output (pages and layout components, search engine, and publishing template).
- Customizing the output using a Publishing Templates package.
- How to embed the Oxygen Feedback Comments Component to collect customers’ feedback.
- Updating DITA topics integrating community feedback using the Oxygen Feedback Plugin.
- webinar editor author developer xml html5 json schema markdown web author content fusion feedback publish engine

Schematron and Schematron QuickFix (SQF) languages can be used to improve efficiency and quality when editing DITA documents. With their use, you can define actions that will add complex structures in your documents (missing table cells, list conversions, IDs and more) and state integrity requirements in order to help you add content more easily and without making mistakes.
This indispensable webinar will be your step-by-step guide to get started as soon as possible with Schematron and Schematron Quick Fixes. Go over topics, such as:
- Creating business rules with Schematron to avoid the common issues when editing documents.
- Defining SQF actions to correct the Schematron imposed rules.
- Configuring and applying specific Schematron rules on DITA projects.
- webinar editor author developer xml html5 json schema markdown web author content fusion

Version 23.0 of the Oxygen XML suite of products was recently released, boasting the most substantial and comprehensive set of new features, productivity enhancements, and customization possibilities in the history of the most powerful XML authoring and development tool available on the market.
To introduce you to the newly implemented and game-changing features of Oxygen 23, we invite you to join us for an overview and discussion that will allow you to engage with the amazing people that envisioned and developed our latest release. Find out first-hand how you can benefit from features like:
- Concurrent editing in Web Author for unrestricted collaboration.
- Opening DITA maps in the Author visual editing mode with the content from all referenced topics expanded and editable.
- The possibility to define or customize how Oxygen supports an XML language using a framework script.
- Updates to JSON schema support and editing JSON documents visually in Author mode.
- The benefits of integrating the Oxygen WebHelp with the Oxygen Feedback platform.
- And so much more.
The panel will bring together George Bina, Radu Coravu, Octavian Nadolu, and Cristi Talau.
- webinar editor author developer xml html5 json schema markdown web author content fusion

As you might know, continuous integration (CI) can be efficiently used to run automated scripts to validate changes as soon as they are saved to a remote repository.
To make things easier for you, we will introduce you to Oxygen XML Scripting, a bundle of command line tools that can be executed inside these continuous integration and deployment pipelines. This way, you can make sure that your project is valid and ready to be deployed at any time!
During this event, we will go over topics, such as:
- DITA validation and checking for completeness - a tool that checks DITA maps and topics to see if they are valid and if all of the relationships between them are working.
- Translation Package Builder - a tool for detecting changes, sending them to translation, and applying the translated files.
- Examples on how to integrate these command line tools into integration servers, like Github Actions or Netlify.
- webinar editor author developer xml html5 json schema markdown web author content fusion
Oxygen Feedback 1

This webinar will present the features of the new Oxygen Feedback comment management platform and showcase its use in conjunction with Oxygen XML Editor to continuously improve your online documentation based on your community feedback.
Some of the topics covered in this webinar include:
- Integrating Oxygen Feedback in your online documentation
- Receiving feedback from your end users (posting comments)
- Comments moderation
- Site users roles
- Site community members management (promote / demote users)
- Site statistics
- Subscriptions model
- Oxygen integration - accessing the comments stream directly in Oxygen
- webinar editor author developer xml feedback introducing
Oxygen XML Editor 22

Have you been looking for a solution that offers support for transforming your DITA content into PDF and WebHelp output?
Look no further! In this webinar, you will be introduced to the Oxygen Publishing Engine – a bundle that contains a DITA Open Toolkit distribution with Oxygen publishing plugins already integrated.
This event will represent a crash-course for you to learn what the Oxygen Publishing Engine is by showing you how to install it, configure it in a Continuous Integration system, and then customize the output.
We will also show its components, various workflows, and you will also get the chance to see how to transform a DITA map document by learning how to:
- Use the “DITA Map PDF – based on HTML5 & CSS” transformation on an integration server using a publishing template for customizing the output.
- Create a custom CSS stylesheet and use it in your transformation to get that extra level of customization for your specific needs.
- Debug the CSS inside both a web browser and Oxygen to see how to choose the correct selectors and properties used for further styling your content.
- webinar editor author developer xml html5 json schema markdown web author content fusion

As a company grows, so does the need for standardized procedures, and when new people enter the company, they often need to be trained to follow existing procedures.
Web Author comes in handy here, allowing you to build guided procedures where new employees don't require additional training or validation.
During this webinar, you will learn various ways that Web Author can be used to enhance your productivity:
- Guiding new writers has never been this easy. With the help of Schematron Quick Fixes or easy-to-configure contextual actions, users can just follow the on-screen instructions.
- Creating forms and sharing them with other users, with the possibility of automated processing.
- Using Web Author to keep track of a standardized procedures (e.g. release notes) with the possibility of filtering out the completed tasks and only focusing on the ongoing ones.
- Document collaboration with real-time co-authoring. Instead of having read-only access to a document, now you can work alongside other users.
- webinar editor author developer xml html5 json schema markdown web author content fusion

If you are a technical writer who wants to be able to define the look and format of your document but struggling to grasp the basics of CSS, then this webinar is for you!
In this webinar, we aim to teach you a basic understanding of the CSS layout to help you to have a better understanding of PDF publishing. Be assured that there is no need for you to have any CSS background to learn the concepts explained during this webinar, but we promise to help get you up to speed by teaching you:
- The basics of Cascading Style Sheets (CSS) and HTML5.
- How to customize your document with the help of fonts, text, and background colors, and by adjusting the position of elements on your page.
- How to debug your CSS document fast and easy with the help of Oxygen.
- How to put your CSS to good use and obtain a deliverable PDF output.
- webinar editor author developer xml html5 json schema markdown web author content fusion

Learn how to process XML documents with a combination of XSLT, the most powerful language designed to process XML documents, and Oxygen, the tool that is most suited for this job!
Whether you are a novice or you have been using Oxygen for years, this webinar will introduce you to a great easy-to-use workflow, as well as many hidden features that you may not have been aware of.
During this webinar, we will also show you how to resolve a variety of problems and how Oxygen can help you accomplish those tasks by introducing you to:
- XSLT editing features, such as the Content Completion Assistant that makes XSLT editing easy and intuitive.
- XSLT validation and how to use Oxygen’s validation abilities with the support of multiple XSLT processors and automatic validation to keep your XSLT document valid at all times.
- XSLT transformations and how to create a simple XSLT transformation scenario and apply it to XML documents.
- XPath Content Completion Assistant that shows the proposed list of XPath functions in the current context, documented with information from the W3C specifications.
- webinar editor author developer xml html5 json schema markdown web author content fusion

Want to make your DITA authoring experience even better?
This is the second of a series of webinars geared towards helping you to get the most out of your overall DITA experience with the help of Oxygen. This particular webinar will cover some of the most important concepts of DITA: profiling and content references. Learn the benefits of knowing how to reuse and profile content in your documents, and how easy it is to do this in Oxygen.
In this webinar, you will learn the following:
- How to filter content in the published output using profiling attributes. This allows you to obtain various outputs from the same documentation source
- How to combine more profiling attributes in condition sets.
- How to apply DITAVAL filters in Oxygen.
- Various strategies and best practices for reusing DITA content in Oxygen.
- webinar editor author developer xml html5 json schema markdown web author content fusion

Do you want to have an improved editing experience? A great way to do this is by learning how to create your own custom Author mode actions.
Custom actions are very easy to create, as they are based on nothing more than a configuration file and ready-to-use built-in operations. Throughout this webinar, you will learn how to implement them and you will see various use cases where they can be used.
At the end, we hope that you will be full of great ideas on how to improve your overall editing experience by learning how to:
- Embed author actions inside a document. This will allow you to present only the relevant actions in a specific context, thus improving the editing experience for novice users.
- Write actions that make use of XLST, XQuery, or JavaScript to edit a document.
- Store the actions to external files so that they can be easily shared between frameworks.
- webinar editor author developer xml html5 json schema markdown web author content fusion

Due to the increasing popularity of using CSS as the customization layer for the DITA to PDF transformation, Oxygen provides a DITA-OT plugin and an engine that generates PDF using CSS called Oxygen PDF Chemistry, making the DITA PDF customization a lot easier, and immediately available to all Oxygen XML Editor/Author users.
As the publishing is triggered by scripts or on integration servers, we also provide the possibility to run the same transformation pipeline that you trigger in Oxygen from a script. This is made available by the new product called Oxygen Publishing Engine, which is the DITA publishing part from Oxygen.
This webinar will dive into all of these capabilities so you can better customize the PDF output of your DITA project by addressing topics such as:
- Customizing tables
- Customizing preserved elements (such as code blocks)
- Content marking and flagging
- Publishing a single topic
- Properly debugging the CSS
- webinar editor author developer xml html5 json schema markdown web author content fusion

The latest Oxygen Content Fusion features empower technical authors to have the ability to restrict task access only to specific collaborators and to track documents revisions. Also, the Subject Matter Experts (SMEs) are involved earlier in the content-related workflows. They can now be proactive and provide content drafts in a structured format or fill in templates designed by technical authors.
For technical authors, sharing XML content is now easier, from complex DITA projects with keys and profiling to DocBook or any other XML vocabulary.
In this webinar, you will learn how you can use Oxygen Content Fusion to:
- Share or reassign ownership of tasks
- Assign tasks only to specific collaborators
- Share complex DITA files that contain key definitions and profiled content
- Share interlinked files in any XML format
- Share templates with SMEs that will be filled in with technical data
- Receive content drafts from SMEs in a structured format
- Track the documents revisions
- webinar editor author developer xml html5 json schema markdown web author content fusion

Web Author comes with out-of-the-box solutions for authoring, but its main strength comes from the vast amount of customization possibilities, providing you with various solutions to address your needs. This webinar aims to inspire you with some of the most exciting ways to improve the authoring experience. You will learn various ways Web Author can be customized and about new framework customizations.
Some of the subjects include:
- webinar editor author developer xml html5 json schema markdown web author content fusion

This webinar focuses on introductory concepts of working with DITA documents in Oxygen XML Editor, covering everything from creating DITA maps and topics from scratch to basic publishing using out-of-the-box scenarios. You will also learn how to edit maps and topics, create references, insert media objects, tables, and other elements, as well as how to benefit from intelligent features such as validation and completeness check for DITA maps.
Covered topics:
- The DITA UI perspective
- Creating and editing maps and topics
- Using the DITA Maps Manager
- Validate and Check for Completeness
- Basic publishing using predefined scenarios
- webinar editor author developer xml html5 json schema markdown

Markdown is a lightweight, plain text markup language and many subject matter experts (such as developers, or engineers) prefer to use it. In this webinar, you will see how Oxygen supports them with features such as:
- Editing support
- Conversion to other formats, like HTML or DITA
- Using Schematron rules to validate and check for completeness a Markdown file
- MDITA, the authoring format of LwDITA that uses Markdown to structure information
- webinar editor author developer xml html5 json schema markdown

Oxygen provides a specialized JSON and JSON Schema editor with a variety of editing features, helper views, and useful tools. In this presentation, you will see an overview of the JSON and JSON Schema support, as well as the new additions, such as:
- An instance generator from a JSON Schema
- XSD to JSON schema converter
- Generate JSON Schema from JSON instance
- JSON Schema annotations
- Schematron validation for JSON
- webinar editor author developer xml html5 json schema

Oxygen provides support for generating HTML5 and XHTML5 documents, and support for editing and validating XHTML5 files. Now Oxygen Editor introduces full HTML5 support, providing features such as:
- Specialized text-based and visual-based editing
- Syntax highlights based on the HTML5 specification
- Content completion based on the HTML5 schema
- Outline view that displays the document structure
- Validation against the W3C validator, including batch validation
- Emmet plugin for high-speed coding and editing
Join us to discover the HTML support in Oxygen!
- webinar editor author developer xml html5

A variety of add-ons are available that can be easily installed to enhance the functionality of Oxygen XML Editor. This webinar aims to take a deeper look at some of the most popular add-ons that are available. You will see how easy it is to install them, the types benefits they provide, and some ideas for how they can be integrated into your particular authoring workflow. Some of the add-ons that will be featured include:
- The Git Client add-on that contributes a Git client directly in the Oxygen interface.
- The Batch Converter add-on that can be used to convert multiple files from one type to another.
- The DITA Outgoing References add-on that contributes a side view where you can see all the outgoing references for the current topic.
- webinar editor author developer xml

Version 22.0 of the Oxygen XML suite of products was released recently and it features the most robust list of additions and improvements in recent years. This webinar will provide a detailed look at some of the most requested and significant features that were added in version 22.0. The primary areas of focus will be:
- New features and improvements for DITA authors.
- New possibilities for DITA Publishing, particular for CSS-based PDF output.
- The benefits of the newly added support for the DITA-OT Project configuration file.
- The most significant improvements added in Web Author and Content Fusion.
- A glimpse of various updates for JSON, HTML, and Markdown users.

Implementing DITA with a small team of technical writers does not have to be expensive or difficult to set up. We'll go through the steps of implementing a DITA solution using GitHub for storage and workflow and Oxygen XML Editor for editing. We’ll also look into how you can automate publishing and receive feedback from your end users. As a practical example we’ll look into how editing, collaboration and publishing on the Oxygen XML Blog works.

Technical documentation is rarely created by lone writers, so there is a constant need for collaboration. Collaboration can be with other writers or with people with other roles, usually referred to as subject matter experts, who may be part of your organization or external experts.
In order to be successful, the collaboration needs to be enabled by integrating it as part of the usual processes or workflows each user performs.
In this presentation, we will explore a few collaboration scenarios that show how to implement continuous improvement loops for published documentation, how to integrate documentation as part of the product development workflow, and how immediate collaboration can take place.
Oxygen XML Editor 21

Within the past year, the Oxygen developers devoted a lot of time and effort into making the JSON support as robust as other document types. This webinar will explore the Oxygen JSON support and the new features that were added in Oxygen 21.
Some of the features and improvements that you will see include:
- Editing JSON documents
- Validating JSON documents
- Querying and transforming JSON documents
- Converting JSON documents
- Future plans

To address comments and requests by the XML community, this webinar will provide an exploration of Oxygen XML Editor/Author from the perspective of a new user. It is meant to be a guide to help users get started accomplishing tasks in Oxygen as quickly as possible.
Some of the things you will learn include:
- An overview of the interface
- Shortcuts and useful actions
- How to configure the toolbars and helper views
- How to migrate non-XML documents to DITA or other XML standards
- How to create a project
- How to create new documents
- Validating documents
- Creating output
- Configuring options
- Search operations
- Inserting tables, images, links, etc.
- Helpful tools

DITA is a great choice for writing technical documentation. Ideally, all contributors to a project should use it to provide content. But sometimes, subject matter experts (such as developers, or engineers) prefer to contribute content in another format. We will explore what possibilities arise when this other format is Markdown, a good match for structured authoring cases in which a minimal markup is sufficient.
Some of the topics covered by this webinar include:
- Structured authoring
- Content and markup
- What are DITA's strengths
- What are Markdown's strengths
- Getting DITA format directly from the SMEs
- Getting another format (Markdown, HTML) from the SMEs and integrating it into the DITA pipelines
- Benefits of each solution
- Challenges that arise when choosing one solution over another
Oxygen Content Fusion

Starting with version 21, the Oxygen Content Fusion connector plugin comes bundled with Oxygen XML Editor/Author. This webinar will provide a detailed look at how to use Content Fusion to collaborate with colleagues during the XML document creation or review process. We will also present details about using your own On-Premise Enterprise Server and various possibilities for customizing Content Fusion to suit your organization's specific needs.
Some of the things you will see include:
- How easy it is to share documents with reviewers
- How to use Content Fusion from a reviewer's perspective
- How to share a template and guide collaborators to provide initial content
- How to communicate with colleagues within the Content Fusion interface
- How to merge suggested changes back into the original content
- How to get the most out of Content Fusion using your own on-premise Enterprise Server
- Numerous possibilities for customizing Content Fusion
- Future plans
- Content Fusion

A detailed exploration of Oxygen Content Fusion, the new collaboration platform designed to make documentation review processes as efficient and productive as possible. You will see how easy it is for a content author to install Content Fusion, share documents, and merge the suggested changes back into their original content. You will also see how simple and intuitive it is for the reviewers to access the documents, suggest changes, and communicate with the content author directly from the Content Fusion interface. Finally, you will see details about using your own Enterprise Server and various possibilities for customizing Content Fusion to suit your organization's specific needs.
The intended audience is content authors, subject matter experts, managers, and anyone involved in the documentation collaboration process.
- Content Fusion
- Collaboration
- Documentation
- Review
- Content author
- Subject matter expert share documents
- Merge documents
Oxygen XML Editor 20

An exploration of Oxygen's less commonly known, but helpful features. Oxygen comes with a lot of functionality specifically designed to enhance your overall productivity. We will explore many of these features, useful shortcuts, side views, specialized toolbars, drag and drop behavior, and editing quirks that will make working with Oxygen more enjoyable.
You will discover a lot of useful features in Oxygen XML Editor, related to:
- Find/replace functionality
- Using your Project view for batch operations
- Shortcuts to navigate between opened documents
- Various Text-editing mode actions and behaviors
- Various visual Author-editing mode actions and behaviors
- Specialized toolbars
- Useful Side views
- Useful tools
- Import functionality
- Various useful global settings

An introduction to setting up and organizing a new DITA project. This webinar is meant to provide guidance and best practice techniques for creating a DITA project from scratch. Some of the things that will be covered include:
- Organizing your project
- Integrating Oxygen with a Git repository
- Migrating other document types to DITA
- Creating document templates with authoring hints
- Organizing your reusable content
- Various helpful refactoring actions
- Saving and sharing project-level options

A step by step guide to getting started with Schematron and Schematron Quick Fixes. When you work on a project, there are a number of constraints or rules that you need to enforce that are specific to that project and cannot be easily expressed in the XML Schema or DTD that describes the document structure. Schematron provides a validation layer that can express and enforce these project-specific rules and Schematron Quick Fixes allows you to specify automatic fixes that can be applied to the documents. Join us to see
- How to create business rules with Schematron
- How Schematron rules are applied in the Oxygen editing environment
- How to enforce specific Schematron rules on all your XML files in a project
- How to develop Schematron Quick Fixes to make it very easy to solve the reported problems
- Schematron Rules
- Quick Fixes

An introduction to Oxygen framework customization. Oxygen offers extensive built-in support for a number of XML languages, such as DITA or DocBook, but the same level of support can be configured for any XML vocabulary. In this webinar, we will take a commonly-used XML model, PI-Mod, and we will create an Oxygen framework that will provide ready-to-use support for PI-Mod XML documents. We will cover:
- Creating the PI-Mod framework configuration
- Setting up validation and publishing
- Creating the CSS styling required to visually edit a PI-Mod document in the Author mode
- Developing various actions to help the writer while working with PI-Mod documents
- Framework
- Create Oxygen Framework

An in-depth look at Oxygen's Publishing Templates feature. Oxygen XML Editor/Author includes some predefined publishing templates that can be selected when configuring a DITA to WebHelp or PDF transformation scenario, but you can also create your own custom templates to define numerous aspects of the layout and style of the output. This webinar is meant to be a tutorial for creating and customizing a publishing template. I will show you how to create a custom template for WebHelp Responsive output, some specific examples of customizing various aspects of the output, and then how to use and customize the same template for PDF output.
- Publishing Templates
- Dita
- WebHelp
- WebHelp Responsive
- Custom Templates

An overview and tutorial for creating and executing unit tests for XSLT and Schematron. A key requirement for any project is the ability to write unit tests that will ensure that you don't alter existing functionality while the project evolves. The XSpec framework is a great tool for writing such tests for XSLT and Schematron, which is why Oxygen offers built-in support for writing these tests. In this presentation, you will see:
- A short presentation of the Test Driven Development concept and an overview of the XSpec framework
- How to create and execute XSpec test scenarios in Oxygen for XSLT and Schematron
- An Oxygen plugin designed to improve the default XSpec support and speed up XSpec test scenario development
- Oxygen
- XSpec
- XSLT
- Schematron
- Unit Testing

In this webinar, we will explore some of the new features and improvements that were added in Oxygen XML Editor 20. The subjects that we will discuss include:
- Customizing WebHelp Responsive publishing templates
- New refactoring actions and validation options for DITA users
- New features in Oxygen XML Web Author
- Productivity enhancements for XSLT developers
- Schematron Quick Fix improvements
- Some exciting new Add-ons that extend Oxygen's functionality
- Improvements in writing unit tests for XSLT and Schematron using the XSpec framework
- Oxygen
- DITA
- Collaboration
- Documentation
Oxygen XML Editor 19
In this Webinar we will present an in-depth view of our documentation workflow to show real world use-cases of how you can use Oxygen products to efficiently and thoroughly collaborate with everyone involved in the documentation process. Some of the details that will be discussed include:
- An overview of the Oxygen team's documentation workflow
- Using an issue tracking application (such as JIRA) for collaboration between all departments
- Using Oxygen Content Fusion for collaboration between the documentation team and developers
- Using Oxygen XML Web Author for collaboration between the support team and documentation team
- Using a combination of tools (JIRA, GitHub, Web Author) for collaboration between the quality assurance team and documentation team
- Using Oxygen XML Editor and a version control system (such as Git) for collaboration between developers and the documentation team
- Using the Oxygen WebHelp system for collaboration between end users and the documentation team
- Oxygen
- DITA
- Collaboration
- Documentation
- Content Fusion
- Web Author

In this webinar, we will explore some of the new DITA-related features that were added in Oxygen 19. The features that we will discuss include:
- Using the "Fast Create Topics" feature to quickly create multiple DITA topics at once
- Easily converting between DITA topic types
- Automatically updating references to DITA resources using "Master Files" support
- Using the "DITA Reusable Components" view to quickly find keys and insert references
- Checking for references to resources that reside outside the DITA map folder
- Using the Content Completion Assistant to select ID values when inserting key references
- Customizing the output using Oxygen PDF Chemistry
- oxygen
- DITA
- Fast Create Topics
- DITA Reusable Components
- Oxygen PDF Chemistry
- Content Completion Assistant
Oxygen XML Editor 18
As a technical writer for Syncro Soft who came from a background of writing in "unstructured" authoring applications (such as MS Word), I have a unique perspective for using Oxygen to write and publish DITA documentation. In this webinar, I will discuss:
- My experience of coming from an "unstructured writing" background to learning "structured authoring" with DITA.
- Our company's documentation workflow and various ways we collaborate as a team.
- Various features in Oxygen that I use as a technical writer to get the most out of DITA authoring.
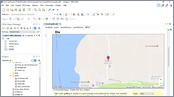
Multimedia content is essential for present-day systems and Oxygen provides support for rendering video and playing audio files directly in its user interface. Additionally, Oxygen can render animated and interactive SVG drawings, and you can interact with the SVG objects directly in the Author mode. Oxygen also offers a graphical editor for creating interactive image maps for DITA, DocBook, TEI ,and XHTML documents. Join us to find out just how easy it is to create modern content with Oxygen and offer it to the world in HTML5-based output formats, such as WebHelp!
A key requirement for an XSLT project is the ability to write unit tests since these tests ensure that you don't alter existing functionality during the project's lifespan. The XSpec framework is a great tool for writing these tests, which is why we integrated it into Oxygen a few years ago. Recently, a new XSpec version was released (0.5.0) and we have also integrated that into Oxygen. In this presentation, I will cover:
Covered topics:
- A short presentation of the XSpec framework
- How to create and execute XSpec test scenarios in Oxygen
- An Oxygen plugin designed to speedup scenario development
Oxygen XML Editor provides support for working with projects, allowing you to organize your files so you can easily access resources relevant to a project. More than this, Oxygen projects give you batch operations that can be performed on all or selected resources and most of the options can be set at the project level, thus facilitating sharing them with your team.
Covered topics:
- Project structure and the Oxygen Project view
- How Oxygen keeps track of the editing context for each project
- Storing options at the project level
- Use cases for using projects including project specific layouts and customizing the authoring experience for a project
- Project specific transformation scenarios
- Performing actions on multiple files
- Master files support
- Refactoring actions
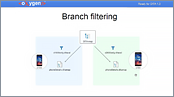
In this webinar we explore DITA 1.3 functionality and how Oxygen XML Editor supports you to take advantage of the new DITA 1.3 features.
Covered topics:
- New domain modules and information types
- Ready-to-use MathML and SVG
- Key scopes
- Branch filtering
- Relax NG constraints and specializations and more
In this webinar we explore DITA publishing options from Oxygen XML Editor including different HTML formats, PDF, EPUB, etc. and how these can be customized.
Covered topics:
- Customizing a transformation scenario, changing parameters
- Publishing using multiple scenarios
- WebHelp customization using the skin builder
- Responsive WebHelp templates
- The WebHelp feedback system
- CSS-based PDF output
- Propagate change tracking and comments to published formats
- Using a different DITA-OT versions
This webinar focuses on introductory concepts of working with DITA documents in Oxygen XML Editor, covering everything from creating DITA maps and topics from scratch to basic publishing using out-of-the-box scenarios. You will also learn how to edit simple topics, create cross references, insert images and tables and how to benefit from intelligent features such as smart paste and validate, and check for completeness.
Covered topics:
- Creating maps and topics
- Using the DITA Maps Manager
- Simple topic editing, cross references, working with tables and images
- Drag-and-drop and smart paste
- Validate and Check for Completeness
- Basic publishing using predefined scenarios

When editing documents there are various rules that you want your content authors to follow, such as grammar rules, document structure guidelines, business requirements, style preferences, or rules for the generated output. To enforce these rules, companies often use grammar checking apps, custom schemas or best practice guides. For content authors, there are usually too many rules to remember them all when writing content. The best approach for this challenge is to signal the user when a rule violation is detected and offer suggestions to help them solve possible rule problems and maintain integrity in their documentation.
Covered topics:
- Guiding users to choose the correct markup in certain situations
- Imposing a set of business rules
- Identifying potential problems in generated output
- Solutions for fixing the signaled rule violations

This webinar focuses on advanced features that justify the return of investment you get from using DITA. REUSE is the key word and it can be implemented either directly through content references or indirectly through profiling/conditional content.
Covered topics:
- Reuse though content references
- Indirect reuse through keys: defining keys, making key references and content key references
- DITA Filtering also known as profiling or conditional content
- Validate and check for completeness in the context of reuse
- Advanced use of profiling using DITA subject schemes

Schematron solves certain limitations that other types of schema have when validating XML documents since it allows the schema developer to define the errors and control the messages that are presented to the user. Therefore, Schematron makes the validation errors more accessible to users and helps to ensures that they understand the problem. These messages may also include hints to help the user to fix the problem, but this doesn't complete the solution since the user still needs to manually correct the issue. This may cause users to waste valuable time and also creates the possibility of making additional errors while trying to manually fix the reported problem. Schematron Quick Fixes provide automatic actions to fix validation errors, thus offering a complete solution, while saving time and avoiding the potential for causing other issues.
Covered topics:
- How SQF integrates with Schematron
- Introduction to SQF by examples
- Schematron Quick Fix language
- Using SQF and XSLT to develop complex fixes
- SQF use case (error correction, refactoring, automatic tagging, etc.)
Oxygen XML Editor 17
Oxygen XML Editor 17 updates the Web SDK to offer a fully featured web editor with a HTML5 + JavaScript user interface, adaptive to every device to work both on desktop and mobile devices.
Oxygen XML Editor version 17 sets the highest standard for XML development and XML authoring. It comes with important functionality updates and focuses on design to make your work not only productive, but also enjoyable.
Oxygen XML Editor version 17 focuses on design to make your work not only productive, but also enjoyable.
The new user interface features Retina/HiDPI icons to make everything look crisp and beautiful, and an optional graphite color theme. Also, the toolbars are configurable down to action level, giving you full control of your work environment.
It is important to have documents without errors, but not all users know how to fix the errors from the documents. Even if they do know, ideally they should use a quick and automated solution.
Oxygen does not only report errors, it also helps you correct them automatically through the Quick Fix support, which provides automatic fixes for XML documents validated against XSD, Relax NG, and Schematron schemas. In the case of Schematron, the schema developer takes full control over the Quick Fix actions, being able to offer custom solutions to any detected issue using the Schematron Quick Fix language.
The webinar includes:
- Generic Quick Fix support in Oxygen
- Quick fix support for XML validated against XSD
- Quick fix support for XML validated against Relax NG
- Schematron Quick Fix language
- Developing custom quick fixes in Schematron
The XML Refactoring tool helps you change the structure of your XML documents.
It offers a wide variety of operations, such as renaming, deleting, and inserting elements and attributes. If the provided operations are not enough, you can create custom refactoring operations and share them with other team members. All of them are available through a friendly user interface and can be applied across a set of multiple files.
This presentation is structured in two parts:
- The user perspective. In this part we will use the predefined operations to solve some common use cases.
- The developer perspective. In this part we will present how to create a complex custom operation and how to share it with your team.
Oxygen XML Editor 17 comes with many new additions to the DITA support.
Topics and maps offer a choice of main rendering styles, as well as the option to add or subtract style layers. Guided DITA authoring was implemented as two optional style layers that allow you to see inline hints and actions. The CSS-based PDF transformation automatically uses the CSS styles you select for authoring, so that you can reuse the same CSS files when publishing DITA to PDF. Both DITA-OT 1.8 and 2.0 are supported and integrating a new transformation is greatly simplified for annotated transformation types, as Oxygen will automatically discover their parameters.
The DITA to WebHelp transformation optimizes the page loading time and provides context-sensitive help support, SEO resources, and LDAP authentication. The WebHelp output that now supports both RTL scripts and Japanese content can be easily embedded in a page.
XSLT Development with Oxygen

This webinar presents the XSLT Quick Fixes functionality in detail and then describes some of the other important features in Oxygen.
Topics covered:
- XSLT refactoring actions
- Support for developing XSLT stylesheets for Saxon CE
- XPath execution over multiple files
- The Ant editor
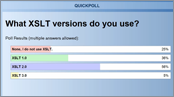
Oxygen excels in offering support for XSLT technology. This webinar covers XSLT development in Oxygen.
Topics covered:
- XSLT editing
- Validation
- Transformations
- XSLT documentation
- XPath content completion
Oxygen excels in offering support for XSLT technology. This webinar covers XSLT development in Oxygen.
Topics covered:
- Organize your stylesheet in multiple modules
- Re-use modules from multiple stylesheets
- Edit modules in context with the help of master files
- Intelligent search and refactoring actions
Oxygen excels in offering support for XSLT technology. This webinar covers XSLT development in Oxygen.
Topics covered:
- XSLT debugger
- XSLT profiler
- Integrated unit testing
DITA Support in Oxygen

In an ideal world, all documentation content would come in one format (and that format should be DITA). But let's face it, content produced in most companies is diverse and comes in many forms and sizes.
So, how can we single source everything? Can we integrate contributors who use formats such as language-specific API documentation, HTML, Markdown, or even Excel spreadsheets or database tables in a DITA-based workflow? Could we convert everything to DITA on the fly? Could we use a magic glass to perceive various data sources as DITA?
We may try to convince everybody to produce DITA content but this may not be always possible. Instead, we can accept these diverse data formats but look at them as different ways of encoding DITA. So, if we put the right decoder in place we will obtain our DITA content.

This webinar focuses on introductory concepts of working with DITA documents in Oxygen, covering subjects such as creating DITA maps and topics from scratch, as well as basic publishing using out-of-the-box scenarios. You will also learn how to edit simple topics, create cross references, insert images and tables, and how to benefit from intelligent features such as smart paste, validate, and check for completeness.
Topics covered:
- Creating maps and topics
- Using the DITA Maps Manager
- Simple topic editing, cross references, and working with tables and images
- Drag-and-drop and smart paste
- Validate and Check for Completeness
- Basic publishing using predefined scenarios

This webinar focuses on advanced features that justify the return on investment you get from using DITA. RE-USE is the key word and can be implemented either directly through content references or indirectly through profiling/conditional content. We will also explore publishing by showing how you can change transformation parameters and how you can obtain multiple output formats from DITA.
Topics covered:
- Re-using content
- Keys: defining keys, making key references and content key references
- Validate and check for completeness using profiling conditions and DITAVAL filters
- Advanced profiling using Subject Schemes maps
- Customizing a transformation scenario, changing parameters
- Publishing using multiple scenarios, each having a profiling condition set applied
- Using a different DITA-OT
XML Authoring for Everyone

In this webinar, we present the Profiling Styles functionality in detail and then go through some of the other important features in Oxygen.
Topics include:
- Setting table properties
- WebHelp Skin Builder
- Extending frameworks
People are usually afraid of using XML authoring because they perceive this to be a lot more complicated than using non-structured documentation, such as a word processing application. The authoring support for XML has been continuously improved in Oxygen and provides user-friendly interfaces, allowing less experienced users to work with XML. These interfaces are a lot easier to use than word processors. In this webinar, we will show a few examples of how Oxygen can make XML editing accessible to everyone, and how you can provide similar user interfaces to edit your own XML formats.

Structured content is considered fundamental to content strategy and an organization's ability to deliver content where it is needed across a wide variety of devices and media. However, in the past, authoring structured content has been quite challenging. Coding raw XML and WYSIWYG authoring is not feasible for most authors. Starting with version 14, Oxygen introduced form controls as a new approach to authoring, hiding the complexity of XML without obscuring the structure we are trying to capture or creating hard-to-understand errors.
For this webinar, Oxygen invited Mark Baker, owner of Analecta Communications and consultant in structured authoring and topic-based writing, to explore a business case for forms-based structured authoring.
Topics covered:
- Why structured authoring is critical to the modern enterprise
- The limitations of current structured authoring methods
- How forms-based authoring addressed these limitations
- How forms-based authoring hides XML syntax better than WYSIWYG
- How forms-based authoring at last delivers the ideal of separating content from formatting
- A demonstration of forms-based authoring in Oxygen
- The benefits to the organization from adopting forms-based authoring
Others
When collaboratively working on documents, support for reviewing is a must have. Oxygen provides advanced reviewing capabilities, including change tracking, annotations/comments, and highlights that work automatically with any XML vocabulary. There are also visual tools to allow you easily see and manage changes and comments in order to get the final reviewed document. This webinar will present the reviewing functionality and how you can take advantage of it in your XML documents.

The XML Schema version 1.1 adds numerous features that improve the usability of the XML Schema standard. These features include assertions, conditional type assignments, open content, override support, default attributes, negative wildcards, substitution for multiple elements, and more. This webinar presents an overview of these XML Schema features, how they work on simple examples, and how you can use them in Oxygen. This is a great opportunity to discover what XML Schema 1.1 makes possible, as well as how easy it is to develop schemas with Oxygen.
"Componize Author" brings together best-of-breed Componize DITA CMS and Oxygen into an end-to-end web-based collaborative solution.
With “Componize Author”, you can enforce processes, information models, and content control with:
- Smart re-use, with easy find-and-insert content, cross-reference, and images
- Automated reviewing and commenting workflows
- Customizable and reusable templates and metadata
- Automated versioning, comparing, and audit trails
- How to author online, quickly re-use information and media, complete a collaborative review workflow, and control your content.
Oxygen users already know that XML makes your content flexible. XML allows you to assemble your content for different types of customers and publish it to all the devices they use. Also, users of the content optimization software of Acrolinx already know that by guiding your authors to use simple and clear language, you can create content that your customers will appreciate. In this webinar, you will see how you can do both through a consistent, powerful, and productive user experience.
Topics covered:
- Five key factors to creating XML structured content with ease
- Six dimensions of content optimization for maximum customer satisfaction
- How Oxygen and Acrolinx work together, along with their special support for DITA
Conferences
DITA-OT Day 2026














tcworld Conference 2024



Oxygen XML Users Meetup - XML Prague 2024








DITA-OT Day 2024


















DITA-OT Day 2022















Convex Tempe 2022

This session will serve as an introduction to the Oxygen suite of products. Here, you will discover everything about our complete solution for XML authoring, development & collaboration.
- Oxygen
- version 24.1

Publishing DITA to HTML is usually done by first resolving content references, key references, profiling and so on and then applying the specific conversion of DITA markup to HTML. This also implies that when a change is made to a DITA file, we need to apply the entire publishing pipeline to account for all the possible changes of the HTML output. Ideally, when something changes to the DITA source we should regenerate only the HTML files affected by that change – an incremental update in the input should result in an incremental update in the output. In this session, we want to explore if we can get closer to incremental publishing if instead of generating static HTML we generate a web application. Can we move the DITA semantics of content references, key references, profiling, etc. inside the web application and have them resolved dynamically at display time? Does this allow us to incrementally update the HTML when an incremental update is made to the DITA source? To get from abstract ideas to a concrete system, we experimented using the React framework by dynamically generating a React application from DITA. Watch our session to learn more about our experience with this approach and to see the results!
- Oxygen
- version 24.1

In this presentation you''ll learn how to convert your existing DITA 1.3 maps and topics to DITA 2.0. Also learn more about how you can create, edit and publish maps and topics which adhere to the DITA 2.0 standard. We’ll go through a list of changes in the DITA 2.0 standard and focus on the changes which affect your editing experience.
- Oxygen
- version 24.1
XML Prague 2022

This session will serve as an introduction to the Oxygen suite of products. Here, you will discover everything about our complete solution for XML authoring, development & collaboration.
- Oxygen
- version 24.1

A framework refers to a package that contains resources and configuration information to provide ready-to-use support for an XML vocabulary or document type. Starting recently, a framework can now be established using a special XML descriptor file, either from scratch or by extending an existing built-in framework (such as DITA or DocBook) and then making modifications to it. During this presentation, we will take an extensive look at this specific method by covering topics, such as:
- What advantages does this new method have over designing a framework in GUI
- Exploring various use cases and implementing them though the script
- Extending the existing built-in or custom frameworks
- Oxygen
- version 24

Oxygen Content Fusion is a flexible, intuitive, collaboration platform designed to adapt to virtually any type of workflow that a collaborative team may use for their documentation review process. Knowing that every team has its own specific methods of collaborating, by joining this presentation, you will discover how Content Fusion helps your team evolve its documentation-review process with:
- Concurrent Editing
- Tracking Changes and Comments
- Full Revision History
- Messaging
- Effortless Editing
- Searching
- Oxygen
- version 23

The goal of this presentation is to show how you can use a combination of Oxygen Tools to develop your online documentation over time. Oxygen Publishing Engine can be used to automate the process of generating publications in both WebHelp Responsive and PDF formats from DITA content. Oxygen Feedback is a comment management platform that can be easily integrated in your published online documentation. The main purpose of Oxygen Feedback is to provide a simple and efficient way for your community to interact and offer feedback. Oxygen Feedback can also be used as a part in a review workflow. Through a specialized view, both Oxygen XML Editor and Oxygen XML Author provide strong integration with Oxygen Feedback. The Feedback Comments Manager view lets the documentation team examine all of the comments that have been added to your WebHelp Responsive output. This means that they can react to user feedback by making corrections and updating the source content without leaving the application.
- Oxygen
- version 23

In this presentation we will take a look at how Oxygen CSS extensions can help you produce complex PDF documents. Some of the topics that will be discussed include:
- Retrieving text content and displaying it in a specific area
- Conditioning the content display based on a document structure
- Calling advanced functions to process your text
- Oxygen
- version 24

With every release we improve our XML support and include new technologies into Oxygen XML Editor. In this presentation, you will learn about the new JSON and JSON Schema support added in the latest Oxygen versions, as well as the support for OpenAPI, AsyncAPI, and JSON-LD. Get the chance to discover the following:
- Smart editing of JSON documents based on the JSON Schema
- Specialized JSON tools
- Editing JSON Schema in design mode
- The OpenAPI, AsyncAPI, JSON-LD support
- Oxygen
- version 23

The already extensive support Oxygen offers for development and technical authoring can be further expanded with a variety of easy to install add-ons. Join the discussion and let’s take a closer look at two of these addons:
- The Git Client add-on that contributes a Git client directly in the Oxygen interface.
- The Terminology Checker add-on that highlights matched terms in the Author visual editing mode.
- Oxygen
- version 23

We encourage your views and recommendations during this Q&A session, as they are an important part of what drives the growth and development of Oxygen. In addition, we will discuss how the Oxygen suite of products will evolve in the future releases.
- Oxygen
- version 23
ConVEx 2021
During Convex 2021, Alex Jitianu analyzed a working Docs as Code setup (freely available on GitHub so attendees will be able to fork it, work with it, gain a deeper understanding and apply these concepts into their own documentation projects). Although any text-based document format works, for the purpose of this webinar, a mixed DITA and Markdown project was used in the demo setup.
- Oxygen
- version 23
In this test kitchen held at Convex 2021, George Bina didn't just focus on a single tool. Instead, he took a step back and looked at the larger picture with multiple tools from Oxygen and other providers, all connected together to form a solution.
- Oxygen
- version 23
In this presentation during Convex 2021, Radu Coravu took a look in those places where the DITA standard meets the tools and the practitioners (where the rubber meets the road) and discuss about: content storage, DITA vocabulary, content reuse, incorporating non-DITA content in a DITA project, link management, terminology checking, and translations.
- Oxygen
- version 23

In this tutorial presented by Octavian Nadolu at Convex 2021, you will learn how to create ISO Schematron schemas, how to use XPath to express your constraints, as well as how to validate your XML files using an ISO Schematron schema and create a report.
- Oxygen
- version 23
Oxygen Users Meetup XML Prague 2020











tcworld conference 2020

tcworld conference 2019







DITA-OT Day 2019














Oxygen Users Meetup XML Prague 2019









DITA-OT Day 2018
















tcworld conference 2018





XML Prague 2018



Oxygen Users Meetup Prague 2018
A variety of new features and improvements that focus on productivity, performance, and efficiency for XSLT development.

The update for the ISO Schematron standard 2nd edition (ISO/IEC 19757-3:2016). Features an improvements in Oxygen XML Editor related to the new standard. The Schematron QuickFix specification has been updated. Now the quick fix messages can be translated in multiple languages, you can generate fixes dynamically, and you can set flags for the sqf:stringReplace regular expression.
When defining an XML structure in a document, you should also provide some sample code. Depending on the way you are creating this sample code, you may get little or no authoring assistance and the consistency of the sample and the description must be maintained manually. In this presentation, I will show an approach to use the full authoring assistance from Oxygen when writing xml sample code and to automatically validate the consistency of your samples with the description.
During the past few years, the Syncro Soft team has worked on providing solutions for collaboration challenges. These consist of creating a browser-based XML editor (the Oxygen XML Web Author), and a collaboration platform called Oxygen Content Fusion. In this session, we will present the latest updates for these products and some use-cases to show how you can use them to engage your entire team in efficient collaboration when working with XML documents.

More and more users are using the visual Author mode to edit documents. Comparing and merging documents directly in the visual Author mode is more appropriate for them. This makes it easier to see how the compared changes will look in the final output once the changes are merged. There are multiple ways to present the differences in a visual Author mode: using Oxygen built-in actions, from an external tool, or from a plugin.

Using the Oxygen PDF Chemistry processor, you can publish XML to PDF using the CSS pagination specification to style the output. In this presentation, we'll look at how Chemistry can be installed and then go over the CSS pagination standard, work with some small examples, and see how various tweaks can be made (change fonts, page orientation, headers and footers, page counters, and so on).
Plugins are a great way to extend Oxygen's functionality through the many built-in extension points. The plugins are also a way for us to offer useful functionality that can be installed on demand. In this presentation, we will present a number of such plugins that we've developed ourselves and we consider them to be quite useful for various audiences. We will also discuss a few other useful plugins that were developed by Oxygen users.
In this session, we'll go off the 'beaten path', try to find some hidden Oxygen functionality, come up with tips to enhance your editing experience or automate your work, and try to have some fun.

Get a preview of the new functionality that will be available in Oxygen version 20 and let's discuss what else you need and what other things are on the roadmap for Oxygen in the future.
DITA-OT Day - Berlin 2017

A quick announcement about the DITA-OT project.
Overview of preprocess2, the replacement module for the original preprocessing routines. This session explains the new approach, why we developed it, and why should you care.

Not only is accessible content often mandatory, it's also just a good idea -- assuming you want your content available to as many readers as possible. This session provides an overview of the accessibility features in output generated by the DITA-OT. While many features are automated thanks to the semantic nature of DITA elements, others rely on you to make sure your content includes everything it needs to. While going over these features, we will explain how DITA-OT handles your content, while also giving tips for how to ensure your content reaches users on all sorts of devices.

Jason will discuss and demonstrate how HERE Technologies extends DITA-OT using open-sourced plugins to continuously validate and build technical documentation. See: https://github.com/heremaps/dita-ot-plugins for more details.
The discussion will cover the design and evolution of the plugins, interaction with end users and how you can integrate the plugins in your own workflows, as well as expected future developments.

DITA includes a lot of markup for syntax diagrams, but it's not particularly useful without a way to render the diagrams. Many years ago Deborah Pickett wrote a group of plugins to render those diagrams as SVG, but they were tied to the "html+" transform type and required an obsolete version of DITA-OT. Last year IBM extracted the SVG diagram feature from those plugins, brought it up to date, and made it usable by other formats (including PDF and EPUB). This session will give an overview of Deborah's original plugins, and explain how anybody can use the updated versions with the latest DITA-OT.

Tips and tricks, mistakes made, and lessons learned: how IBM manages a single build environment for hundreds of authors with 50+ plugins -- including new doctypes, new transform types, and externally contributed plugins -- while keeping up with the latest DITA-OT releases.

This talk provides an overview of DITA-OT documentation usage metrics and highlights recent changes to the docs and ideas for future improvements. We’ll close with room for suggestions from the community and a call for contributions with information on the browser-based workflow for suggesting changes.
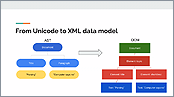
Description of how Markdown support was added to DITA-OT to make Markdown a first-class file format for DITA content. Focus is on the implementation details and goals instead of Markdown author perspective.
Using CSS to produce PDF from DITA content is way easier than writing plugins and customizing XSLT stylesheet and will probably become in the future the most used way to produce a PDF. We will go over the existing solutions for producing PDF from DITA using CSS and maybe try to show a little bit of the CSS pagination standard: change the front matter and backmatter, change headers and footers, change some colors and styles, change the paper type and orientation.

Web developers often use CSS frameworks, HTML5 boilerplate or component libraries like Bootstrap or Foundation to quickly build robust, responsive sites. With custom HTML plug-ins, DITA-OT can be extended to produce HTML5 output that makes use of these common templates so that generated documents can build on existing front-end solutions. This talk will outline the process, using the DITA-OT project website at dita-ot.org as an example.

This presentation illustrates how an OT plugin can leverage CMS status information to create a PDF for review that includes only the content SMEs need to look at, or alternatively, include everything for full context but highlight the specific content that needs reviewing. This presentation demonstrates how to quickly create a PDF that includes material for a specific reviewer, and how to create a PDF intended for multiple reviewers with their names assigned to each topic.

Presents the DITA Community i18n Plugin, which provides an integration with the ICU4J libraries. The i18n plugin provides support for locale-specific grouping and sorting, including dictionary-based Simplified Chinese, as well as facilities for doing locale-specific word and line breaking.

Short overview of the DCQL attribute domain and accompanying code that allows pulling DITA content in from SQL or XML databases at publish time or runtime, and even keeping the data link alive on interactive media.
This is a feedback session where we want to hear from you! One problem with DITA-OT development is that we don't usually know what our customers like most, what they're using, and (almost as important) what they're not using. It's also likely that in some cases, we're not sure what to ask. In this session we'll discuss potential ways of getting this feedback, related issues such as data privacy, and ideally take suggestions from the audience for improved communication.

tcworld conference 2017

Oxygen Users Meetup Prague 2017

Oxygen provides support for Markdown, but unlike other Markdown editors it supports Markdown from an XML perspective, focusing on using Markdown in XML-based workflows. We can leverage Oxygen SQF functionality to use Markdown syntax as an entry point to learn an XML markup language by automatically recognizing and converting different Markdown structures to a specific XML format.

Multimedia content is essential for modern systems and Oxygen provides support for rendering video and playing audio files directly in its user interface. It also offers a graphical editor to create interactive image maps for DITA, DocBook, TEI and XHTML documents.

Oxygen provides special support for Lightweight DITA, designed to show how the authoring experience can be tuned for a group of people without technical knowledge, hiding the underlying XML structure and providing inline placeholders and hints, actions, allow to edit properties, etc. We explore the user perspective and then show also how this authoring experience can be created.
Oxygen provides different ways to enable creating a controlled authoring experience, to allow people to create structured content without previous training to learn the actual XML structure. Join us to discover how to approach customizing the authoring experience and some of the new functionality Oxygen provides to facilitate this.

Discover a new product from Oxygen that allows you to share and collaborate easily on XML documents.
Explore available connectors for different repositories, discover the available API for integration and see different integration examples.

When different contributors work on the same set of XML files, using a versioning system (like Git or SVN) or just a collaboration platform, they need a tool to visualize and merge the changes. Most of the diff/merge tools are not using an XML comparison algorithm to determine the differences. Oxygen offers tools to compare and merge files using XML diff algorithms.
During this session you will see:
- three-way XML comparison
- integrating the Oxygen XML diff as external tool
- merge directories
- using the merge support form a plugin

Discover the latest additions to the Schematron and SQF support in Oxygen and the new support for business rules checks and corrections added to the Oxygen XML Web Author.

Saxon-JS is the successor of Saxon-CE, but its implementation and support is different, it runs only Saxon compiled stylesheets. As Oxygen updated its support for Saxon to work with the latest version, we considered also users of Saxon JS and we enable you to compile stylesheets to be used with Saxon-JS.
Some of the Oxygen functionality is made available also in the form of command line tools which can be used as part of CI processes to enable automatic checks, generating reports and automatic publishing. Join us to discover how you can use these tools from continuous integration systems.

This session presents a real-life localisation project, where a web page will be localized (translated and adapted) in accordance with conventional steps of the industry. The major focus of the session is XML Localisation Interchange File Format (XLIFF), an OASIS standard generally used for data exchange among the localisation steps. We will demonstrate the XLIFF framework of Oxygen Editor which has been recently empowered with an advanced validation platform in accordance with the latest XLIFF development.
We will also introduce the FREME project which intends to enrich the digital content by harvesting the available data on the web (e.g. DBpedia). Finally, the possible integration of FREME into Oxygen will be discussed to highlight how the Oxygen Editor could benefit from such integration.

A key requirement for an XSLT project is the ability to write unit tests because these tests ensure that you don't alter existing functionality during the project's lifespan. The XSpec framework is a great tool for writing these tests, which is why we integrated it into Oxygen a few years ago. Recently, a new XSpec version was released (0.5.0) and we have also integrated it into Oxygen. In this presentation, you will see how you can take this support even further through an Oxygen plugin.
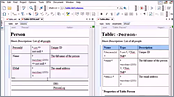
XML is widely used to store almost any kind of data. It is very suitable for automated processing but somewhat cryptic to edit manually. DITA is widely used for technical documentation and there is great support for visually editing and publishing to various formats. This presentation will show an approach to combine these two standards. That is, to apply DITA tools (i.e. Oxygen for visual editing and DITA-OT for publishing) on non-DITA XML documents without the need to implement a transformation for it.
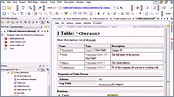
Almost any modern integrated development environment - including Oxygen - provide great support for dealing with identifiers within source code. When writing documentation or functional specifications for software it is likely to use several identifiers as well. But currently DITA provides only very limited support for handling a large amount of identifiers. This presentation will show an open-source custom extension (DITA-SEMIA) that enables the use of identifiers within DITA documents in a similar way as when writing source code.

Get a preview of the new functionality that will be available in Oxygen version 19 and let's discuss what else do you need and what other things are on the roadmap for Oxygen.
DITA-OT Day 2016


While tools can be used to simplify many things, localization can still be scary. In this session, we'll go over how the toolkit is set up to handle publishing in multiple languages: what comes out of the box? What should you expect to do on your own? And how has this changed over the last few releases? Also: stories of panic from the past!

This session shows 7 DITA Open Toolkit open source plugins that the developers of Oxygen XML have created or updated this year including:
- DITA + CSS = PDF - This pre-existing plugin now was updated to add support for showing Oxygen track changes and comments.
- DITA Classic PDF Review - This plugin adds support for showing Oxygen track changes and comments in the classic PDF output.
- Media Support Plugin - Plugin which adds the possibility to embed videos (including YouTube videos) and audio resources in DITA topics and publish to HTML and PDF.
- DITA Merged - Plugin which produces a single merged XML file from the entire DITA content.
- DITA Relax NG Defaults - Plugin which adds support to a DITA-OT distribution to process Relax NG-based topics and maps.
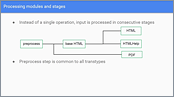
The internals of DITA-OT are in perpetual motion and most of these changes are not visible to end users. In this talk we go through changes in the black box and describe future development plans.
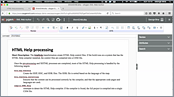
Now it is very easy to contribute to the DITA-OT documentation - just read the developer docs and use the "Edit" button to open the source topic from GitHub for editing. Save will automate all the contribution process, sending a pull request with your proposed changes.

This talk provides an overview of recent changes to the DITA-OT documentation, points out open issues, highlights ideas for future improvements, and closes with room for suggestions from the community, a call for contributions and a brief demonstration of the pull request approval process that is applied when people submit changes to the development documentation via the /Edit this Page/ links.

There are some significant changes to DITA-OT 2.x that can make upgrading PDF plugins written for earlier versions of the OT a challenge. Having just upgraded several plugins, and released a new edition of "DITA For Print," Leigh will share a few of the major things to look out for.

Docker containers make it easy to package and use different configurations of software components. Docker containers can also provide the dependencies needed to run a given piece of software. For the Open Toolkit, you can use Docker containers to easily provision and run the Open Toolkit without worrying about the local Java configuration or other dependencies. Docker also makes it easy to set up custom configurations of the Open Toolkit or use different versions. This presentation shows how to use Docker-based Open Toolkit packages.

This presentation will show how SAP has integrated the DITA Open Toolkit to create a large scale production infrastructure able to create daily builds producing 50 000+ outputs for all SAP Product documentation. This covers the end-to-end process from getting the DITA content from the CMS to publishing the produced outputs to the appropriate delivery channels, using so-called project maps as a key ingredient. Advanced features like peer linking across outputs will be shown, as part of the overall implementation.

Jarno and Robert will discuss how the DITA-OT is tested, get feedback and talk about where we want to go.
Fixing errors during authoring stage is cheap in both technical communication and software development; fixing errors after publishing is expensive. In this talk I demonstrate a QA method for software documentation in DITA.

I'd like to present how we manage and check terminology using the org.doctales.terminology plugin..
A DITA to simplified/resolved DITA transformation provides a solution for some of the possible issues with translating DITA. There are also other advantages, especially in connection to the increased dynamics in DITA-OT development. Join me to discover how a DITA to resolved DITA can help you!

Kris and Robert will discuss the long term future of DITA-OT: what can we all do to ensure the continued health of this critical piece of the overall DITA infrastructure?

Oxygen Users Meetup Prague 2016

Based on the Oxygen XML WebApp technology introduced 2 years ago at XML Prague, Syncro Soft releases a new product, Oxygen XML Web Author, that provides browser based XML authoring support. This is a web application that comes with connectors for GitHub, and SharePoint while additional connectors can be plugged in and easily configured.

Different types of users working with different XML vocabularies imply different authoring needs. Having this in mind, Oxygen 17.1 provides the means to tailor the authoring environment for specific needs by supporting a new range of CSS properties. We will go through some of these properties and we will present scenarios in which they are helpful. We will also go over another mechanism in Oxygen, designed to help with structure insertion and to keep the document valid. We will quickly remind you of this “smart editing” feature, how you can extend it even further and present what we've improved in the upcoming Oxygen version 18.

Due to the feedback that we received from our users, Oxygen has continued to improve the support for Schematron and Schematron QuickFix (SQF). You can use XSLT 3.0 in Schematron schemas and as well as multilingual messages. Oxygen extended the SQF support for resolving errors in documents other than the current one and allows the users to specify values to be used when executing a fix.

The content completion support in Oxygen is driven by the schema but there are cases in which these values come from an external data source or the schema can't be altered. To handle these situations, in Oxygen 18.0, we've added support for a configuration file that allows not only to specify attribute/element values but also to restrict the elements and their children.
Oxygen version 17.0 and 17.1 focused a lot on design to make a more intuitive and enjoyable working environment. We will cover the new Color Themes and User-defined themes, the customizable toolbars and the HiDPI and Retina support.

An interesting way of applying conversions dynamically is to encode the conversion process as a custom URL implementation. Oxygen implements a custom URL by registering the "convert" URL scheme and allows you to specify within the URL different processing steps (based on XSLT, XQuery, Java, JavaScript, etc.) that can be applied on a target content. We will present this idea together with examples of how this can be used. Finally, we invited Claudius Teodorescu to share how he used this functionality in one of his projects.

Applying line based diff algorithms for detecting the changes in XML documents when a versioning system is used is not ideal, as these algorithms ignore the XML structure and thus they present a lot more changes than the actual XML changes. A three-way XML-aware comparison of documents solves this problem. This is one of the core functionality we have been working on during the last months and which we hope to make generally available in the next Oxygen version. Another interesting aspect is the possibility to compare documents in the Author visual editing mode instead of the Text editing mode - this is another area that we explored and we want to share the results with you.

DITA-SEMIA is a set of open-source tools that support information architects creating specialized, semantic DITA frameworks. The plugins integrate well with the Oxygen XML editor and DITA-OT to support both authoring and publishing. The session will give an overview of the features currently available and planned for the near future.
This includes:
- XSLT-Conref: An extension of the standard conref concept of DITA with an XSL transformation.
- XSLT-Gui: A Set of Saxon extension instructions that allow interaction with the user from within a transformation scenario or XSLT author operation.
- Content by Attributes: Allows to set predefined content (e.g. titles, table headers and prefixes) for specialized DITA elements within the schema using attribute default values without the need to individually customize the CSS or DITA-OT.
- Advanced mechanism for defining and referencing keys: Allows to implicitly define key values with type, name, namespace, and description and comfortably reference it.

Meet Oxygen developers and see what is planned for the future. Ask any question and we will be happy to respond. Share your feedback with us and with the other Oxygen users!

The support that Oxygen provides for XML vocabularies can be customized to match various audiences' requirements through an extensive array of extension points. To facilitate such customizations, we provide a start-up project that contains samples for every major type of extension.
In this workshop we will present:
- The structure of the SDK sample project with emphasis on what each module does and in which situation it can help.
- The structure of an Oxygen's plugin.
- The difference between the text page API and the author page API.
- The creation of a sample plugin that contributes a toolbar and a sample view. This view will use our API to interact with the text page and the author page.
DITA-OT Day 2015

What's new in DITA-OT? We'll cover major changes in both 2.1 and 2.2, with a focus on support for new DITA 1.3 features.

What might often seem like a good way to use or extend DITA-OT, but likely result in trouble later? What is the alternative? This session will cover known traps that organizations have fallen into when using DITA-OT, and suggest how to avoid those issues or (perhaps with difficulty) recover from the mistakes. The session will leave time for discussion about other traps that audience members may have fallen into.

The startcmd batch script made it possible for many to easily use DITA-OT, but whether you realize it or not, it's no longer really necessary. I'll briefly explain where it came from, why it was always more of a kludge than a Feature, and how better DITA-OT designs mean it's no longer needed.

This talk introduces Jarno Elovirta’s DITA-OT Markdown plugins, which extend the DITA Open Toolkit so you can use Markdown files directly in topic references and export existing DITA content in Markdown format for use in other publishing systems. This makes it easier for people to contribute content to DITA publications, enables mobile authoring workflows, facilitates review processes with less technical audiences and expands the range of publishing options to workflows based on Markdown.

Presenting new updates made to the DITA-OT plugin which can now be used to generate PDF from DITA and CSS using either Prince XML or Antenna House.

When creating a product, a good design is critical; in many cases, this rule applies not only to the outside, but also to the parts inside that normal users will not see. Unfortunately, to those who looked, the inner workings of the early toolkit seemed to have almost no design at all. In this session, we'll talk about how Jarno has cleaned up the hidden inner workings of the toolkit -- and how everyone benefits from these changes to things they might never see.

Professional writing can require several features that the present DITA-OT (2.1.1) has not implemented. There are several expensive plugins available as commercial products to improve that situation. Helmut Scherzer presents a match to highly professional DITA-OT extensions which contains a list of more than 20 new powerful features to PDF2 – offered to become part of the public DITA-OT.

The DITA Community GitHub organization serves as a general place for people to contribute DITA Open Toolkit plugins and other DITA-related tools and utilities that are not maintained by DITA-OT or other projects. This presentation provides an overview of the DITA Community organization, what's there today, and how you can contribute.

This presentation will address the problem of creating DITA constraints/specialisations to customize DITA to meet your specific needs. We will identify a problem, create a Relax NG constraint/specialization to solve it and convert that to DTD. All these will be packaged as a DITA-OT plugin.

There are multiples ways to run DITA-OT and some of them are good, some are bad, and some are just plain ugly. This presentation goes through different interfaces to DITA-OT and when to use them.

Each DITA-OT plugin provides a set of parameters that can be configured to customize the publishing process. As these need to be made available to users it is important to have an automated way of discovering these parameters and additional information about them - what they represent, what values are possible, etc. DITA-OT makes this possible by allowing parameters to be annotated.

Publishing from a CMS imposes specific requirements on the DITA-OT. We will review these requirements while showing how IXIASOFT integrated the DITA-OT into their Output Generator.

Over a couple of years, the Gnostyx team has been preparing and refining a DITA Demonstration Data Set. It's purpose is to provide members of the community a functionally realistic data set with which to demonstrate DITA based applications. It was made available publicly in early 2015 and has since been adopted and used by several members of the DITA Community. This talk is really a demonstration of some of the business use cases that we use to convince business stakeholders that DITA demands serious attention. People will learn a little about the DITA Demonstration Data Set and some of the sales pitches that they might want to use, and to demonstrate, in the future.

If you need to maintain multiple configurations of the OT for day-to-day or minute-by-minute changes to the OT for different projects, clients, etc., you can use git to do it. There are some tricks and gotchas but it does work.

This talk provides an overview of recent changes to the DITA-OT documentation, points out open issues, highlights ideas for future improvements, and closes with room for suggestions from the community and a call for contributions.

Oxygen Users Meetup London 2015

Discover the new functionality added in version 17 and how that helps you.

Learn how to create XML authoring interfaces that take advantage of the new functionality added in Oxygen 17 - functionality that allows defining custom actions in CSS and to place them directly within the document on different layers as well as using the new HTML content form that can bring hints as static content inside the document. See how this was used to provide enhanced DITA editing support, a nice editor for Saxon configuration files and ISO StratML editing.

When a problem is identified in a set of documents it may occur multiple times, sometimes thousands of times. In order to fix such problems we need a way to change those documents in a controlled way and we can do that with XSLT and XQuery but we need to keep as much as possible the same serialization and formatting of the documents and this is a little challenging. Alex will present the new refactoring support that allows to apply XSLT and XQuery updates on documents while trying to preserve their initial content. This can be used through a simple UI built on top of available scripts to allow also casual users to take advantage of available refactoring actions.

Identifying an error is only the first step in correcting a document - you need also to understand the problem and perform the actions to fix it. Quick fixes offer a choice of possible actions that will fix a reported problem automatically. See how Oxygen implemented quick fixes for XSLT and XML documents and discover Schematron Quick Fixes - a language that allows you to define your own quick fix actions.

Web based authoring was presented at XML London last year on mobile devices. See how this evolved and a few sample applications of this technology that make XML authoring and review accessible across platforms and devices.

DeltaXML provide a quick and simple way to run their change management tools from within Oxygen using a plugin Add-on. Tristan Mitchell will give an overview of the functionality provided in the Add-on and the Oxygen features it relies on, and will demonstrate how easy it is to identify and publish changes without leaving the Oxygen interface.

Oxygen XML provides systems integrators with the APIs they need to integrate directly into 3rd party content management platforms. This presentation shows how Mekon have made use of these APIs to provide an editing and system administration front end to their content delivery platform, DITAweb.
Oxygen Users Meetup Prague 2015

Identifying an error is only the first step in correcting a document. You also need to understand the problem and perform actions to fix it. Quick Fixes offer a choice of possible actions that will automatically fix a reported problem. See how Oxygen implemented Quick Fixes for XSLT and XML documents and discover Schematron Quick Fixes (a language that allows you to define your own quick fix actions).
Every company has a best practices guide, but it's impossible to learn it, by heart, before starting to write. The best approach for this challenge is to dynamically provide hints, based on the context in which the user is working. The document becomes the entire interface and guides the user through the authoring process. Alex will show you how to achieve this goal by using features that are already available, as well as a few new ones that are coming in version 17.0.
These include:
- a new type of form control
- new alternate CSS functionality
- defining actions directly in CSS
- absolute/relative/fixed CSS positioning
- the new CSS Inspector view
Web-based authoring was presented at XML Prague last year on mobile devices. See how this has evolved, along with a few sample applications of this technology that makes XML authoring and review accessible across platforms and devices.

DITA-OT Day 2014

Are you new to the DITA-OT? Come and get an overview of what it is, how it works, its history, and the people involved. This will be an excellent start to DITA-OT day for novices.

Participate in a deeper, more technical dive with the primary DITA-OT developer. This session will cover the pre-processing architecture of the DITA-OT and information about the output transformations.

Now that the toolkit is hosted on GitHub, it's easier than ever to contribute changes to the DITA-OT code. Roger will demonstrate how to fork the repository, create a new branch, change the necessary files and submit a pull request.

The new version of DITA, version 1.3, will use Relax NG as the normative grammar to express the DITA content models. George proposed this idea and provided a working prototype under the DITA-NG open source project and Eliot took this further making it an official proposal for DITA 1.3 and finalized its implementation. See how Relax NG simplifies the way DITA content models and specializations are defined and what other benefits it brings to DITA 1.3.

DITA-OT includes extension points that let you do any number of things. This session will cover what's available, what you should or shouldn't extend, and give out sample plugins to slice and dice your content.
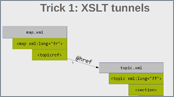
The dita2rdf plugin is meant to extract metadata from DITA content and produce an RDF/XML output, which is a serialization of the W3C RDF standard. The final objective is to get insights from the DITA content by querying its metadata as a graph, not as a tree-like in XML. It also potentially enables the connection of the DITA metadata with other types of entities such as products, people, events, etc.
With a few simple changes, it's possible to give the DITA-OT's default PDF output much of your own look and feel. If you need to develop a DITA proof of concept for your organization, these changes might be all you need to get the ball rolling. Join Leigh to find out what's easy to do, what's not quite so easy to do, and where the real heavy lifting is.

Did you know that you can create customized PDF plugins using an easy online tool? Join Jarno for an overview of his plugin generator, what it produces, and his work developing the dynamic Web interface.

How about producing and styling PDFs only by using CSS? Join Radu for an overview of a new, innovative, open-source DITA-OT plugin, which produces PDF from DITA content using CSS and an XML+CSS to PDF engine such as the Prince XML or Antenna House engines.
Hal Trent of Comtech will present a SCORM wrapper developed for learning and training output, which could be potentially donated to the DITA-OT. The wrapper incorporates the current DITA to SCORM output and adds a layer of JavaScript with the SCORM API to integrate the output generated from the DITA-OT into an LMS. The wrapper passes test completion status to and from the LMS and provides a much needed output for the learning and training implementation.
 09:17
09:17On the example of ice hockey rule books, we show how easy content can be re-used by creating new context variants and how it can be published to EPUB or into an Eclipse help infocenter.

Discussion about the present and the future of the DITA-OT project.
Oxygen Users Meetup Prague 2014

Alin presents a newly introduced set of actions, available for highlighted content and designed to assist the user in quickly solving time consuming repetitive tasks such as fixing XML structure errors, renaming multiple occurrences of an attribute or even correcting misspelled words.

XML tools usually support editing with different helpers, taking advantage of the schema information. What happens when there is no schema, how can a tool assist users to create XML content in the absence of a schema or a DTD? Let's discover what support Oxygen offers that does not look into a schema but into the document itself.

Oxygen does not provide yet support for Saxon-CE but Radu will show you that there are some things you can do to be able to develop XSLT stylesheets for Saxon-CE.

A quick demo about how to use the 'vc:minVersion' and 'vc:maxVersion' attributes for XML Schema. Oxygen automatically detects the version set for the current XML Schema document, and configures the validation and the Content Completion Assistant accordingly.

The support for developing Schematron schemas was improved a lot in the last release of Oxygen to include enhanced validation of the Schematron schema, search and refactoring actions. See what is new on developing Schematron in Oxygen.

What if some values in the XML document are contained by an external data source? Alex will show you how you can configure Oxygen to assist the user to select values defined outside the XML document, in external data sources.

See how you can use Oxygen to import existing data from relational databases, Excel sheets or text file (CSV files, tab separated values, etc.) as XML, so you can process that further with XML tools.
We will demo how to turn Oxygen into a text analysis tool. The demo is based on freely available automatic text analysis Web services and the Oxygen customization facilities. The DocBook 5.0 type has been adapted to allow automatic annotations of entities, while preserving the original DocBook markup. Use cases are, for example, disambiguation of named entities to ease localization of content
The main goal while working for the digitisation of the Romanian Academic Dictionary was to provide an easy way to create dictionary entries while using Oxygen, along with reducing the information entered manually, as this can lead to human errors.
For this, they adopted the Author editing mode that allows a fast and easy way of styling the XML using CSS. By using CSS extensions authors can use text boxes, text area, combo boxes to edit XML data, buttons to trigger specific actions, as well as other various in-house developed components.

See how you can work with DocBook modules, referenced through XInclude or as external entities, taking advantage of the Master Files support.

Copy/paste is a simple way of exchanging information between applications and implementing this intelligently allows to automatically convert from spreadsheet formats to XML and back, from different office applications to specific XML formats and to get nicely coloured XML code in your email.

Is it possible to get people that are not familiar with XML to create XML content? The answer is yes, but some work is needed to provide them a customized user interface that is tuned to use the concepts they are familiar with and that makes the editing easier. Alex will show you how such user-friendly XML authoring interfaces look like.
When you create XML content you may need to reference some other information from your current project but you do not know where exactly that information is. If you work on a project together with your colleagues and some of them annotated some files, how can you find those annotations to look over them? The advanced search for resources provides the answer to these questions and more.

Oxygen supports user-defined pseudo-classes in CSS and these can be used to create a better user experience when editing XML documents. Alex will show you some examples of using this new functionality.

Oxygen Users Meetup Prague 2013




Oxygen Users Meetup Munich 2013

Watch the exclusive preview of the Oxygen XML web/mobile editing platform